
目前国内外各种人工智能的话题层出不穷,同时国内各大公司也在做相关的大模型的研发。对于普通人的我们如何找机会呢?我的答案是在应用层寻找机会。
对于人工智能大模型来说,其实国内只有大的企业才会去涉及到大模型的开发,因为这涉及到非常多的资源消耗,这些资源不是一些小公司或者中型公司所能承受的,但是对于大公司来说,近年来各种降本增效的裁员情况大家从互联网上都有听说。所以对于真正不是尖端优势的人来说,去做大模型开发是一条很难走通的路。所以为了分到一杯人工智能大模型的羹,我们要善于去寻找自己能走的路。所以基于此,我个人认为我们把大公司开源的模型拿来在垂直行业进行使用及训练,也就是专注业务层,应用层,这将是一条很好走的路。
目前基于Ollama及各种开源的大模型来说,我们只需要借助这些开源的大模型及大模型部署工具来实现自己的业务是一条非常棒的选择,特别是对于一些想转行的同学来说,学会这个,目前一些初创公司会有这种大模型的需求。这也是一个非常好找工作转行的捷径。
本文我们开始正式进入人工智能AI本地大模型的实施了。既然是本地部署大模型,那么我们就要开始各种安装部署了。本文我们主要介绍ollama的部署。
在本地部署人工智能大模型的时候,我们最常使用到的就是ollama这个开源框架。这个开源框架的官方解释是:
Ollama是一个开源的 LLM服务工具,用于简化在本地运行大语言模型,降低使用大语言模型的门槛,使得大模型的开发者、研究人员和爱好者能够在本地环境快速实验、管理和部署最新大语言模型,包括如Llama 3、Phi 3、Mistral、Gemma等开源的大型语言模型。我们再打个比喻来解释下什么是ollama。
ollama就相当于一个docker环境,也就是AI大模型的管理平台,大部分开源的大模型,我们可以直接在ollama上进行安装部署。这样子的理解是不是比较清楚了。
所以要在本地实现大模型的话,我们首先需要安装部署一套ollama环境,下面我们演示一下。
这里我们在服务器上安装部署ollama,所以对应的环境主要是linux系统,大家要准备在本地部署大模型的话,建议统一使用服务器linux系统,同时cpu,内存这些尽量大一点,比如16C64G这样的配置。
想要安装ollama的话,他的安装包比较简单,我们可以去官网:Ollama 下载即可(打开这个首页就会直接看到下载按钮)
点击Download即可下载,这里我们选择linux版本即可,他是一个脚本
我们把它复制下来,完整的内容是:
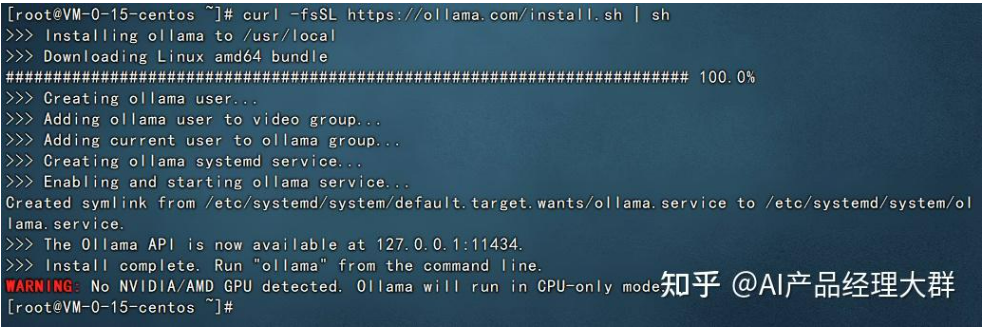
curl -fsSL https://ollama.com/install.sh | sh接下来我们就去服务器进行安装即可,执行上面的curl命令,示例图如下:

执行之后,服务器就会开始自动下载及安装。稍微等待片刻即可。出现如下界面就代表安装完成了。
备注:
1、这里在安装的过程中国内网络问题可能会比较复杂,建议使用香港的服务器来实施。
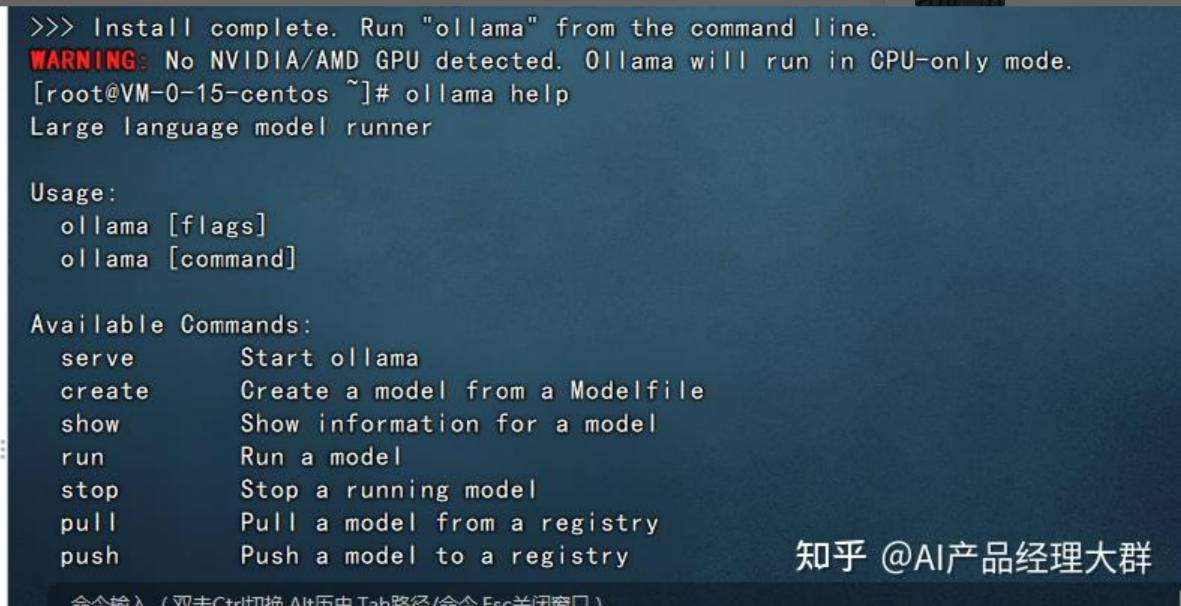
至此,我们的ollama环境已经部署完成了,在控制台我们可以使用
ollama help查看ollama如何使用。
ollama启动完成之后会提供一个11434的端口供其他应用程序访问,示例如下:

从上图大家发现问题没?ollama提供的11434端口仅支持127.0.0.1访问或者localhost访问,不支持使用服务器的ip进行访问,所以这里我们需要调整一下,让11434端口供其他程序可以访问。
1、修改 /etc/systemd/system/ollama.service文件,添加上
Environment="OLLAMA_HOST=0.0.0.0"
Environment="OLLAMA_ORIGINS=*"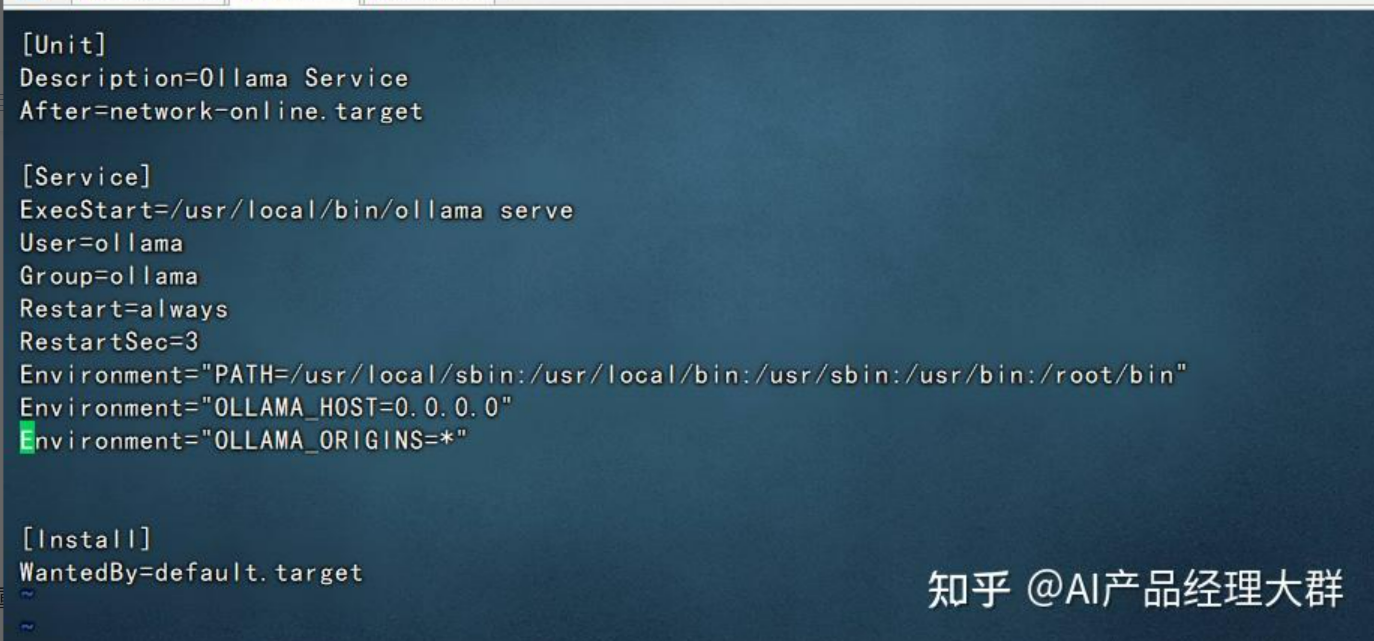
2、重启ollama
systemctl daemon-reload
systemctl restart ollama此时我们再查看11434端口就是可以直接使用ip进行访问了:

再使用浏览器访问看看

本文我们来演示一下使用ollama部署阿里开源的Qwen2模型。
Qwen2模型是阿里巴巴开源2024年6月发布的的大模型,官方的解释是:
Qwen2所有尺寸模型都使用了GQA(分组查询注意力)机制,以便让用户体验到GQA带来的推理加速和显存占用降低的优势这里由于我们的服务器配置低,所以我们部署Qwen2-7B模型即可。下面演示下如何安装。
首先我们进入到刚才安装了ollama的服务器,执行如下的命令:
ollama run qwen2:7b然后系统就会自动开始安装qwen2-7b模型了,如下图:

稍等片刻,看到如下的界面就代表qwen2-7b模型安装好了。
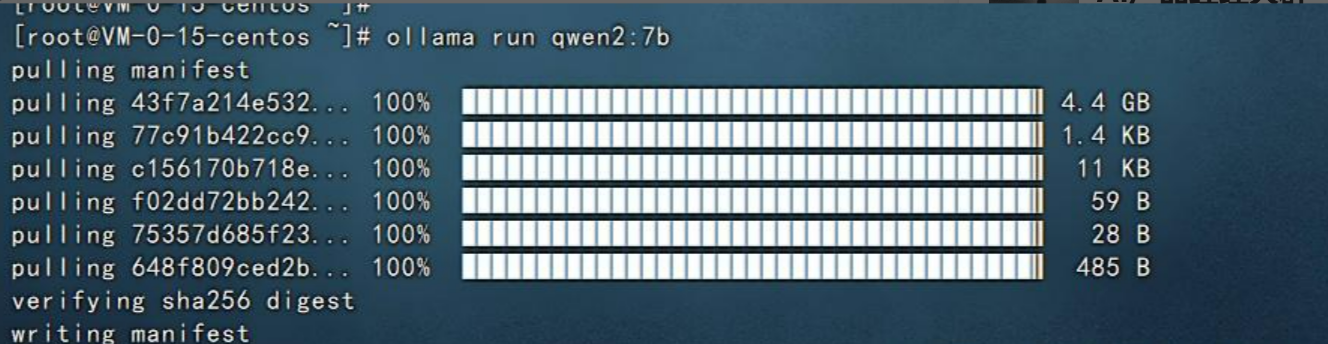
在最后可以看到让我们输入问题,他可以进行回答,比如我们输入:你叫什么名字,然后回车就可以看到他开始回答了。如下图:
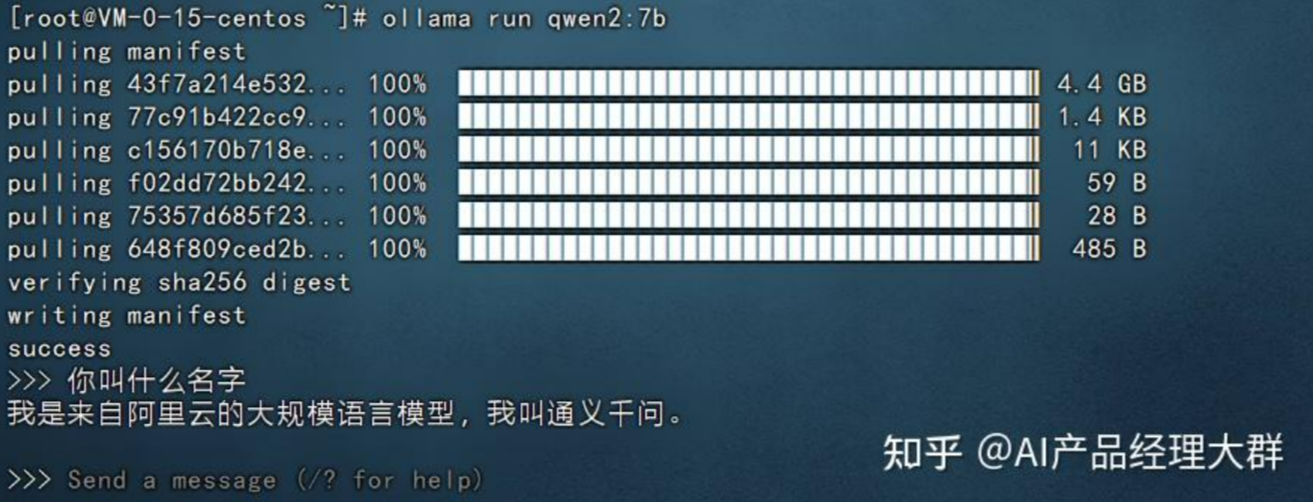
以上就是在本地部署qwen2-7b大模型的案例。
安装好Ollama后,打开命令行界面(CLI),提取模型:
ollama pull deepseek-r1:1.5b
您可以在这里探索 Ollama 上的其他 DeepSeek 模型:https://www.wbolt.com/go?_=35a37498b4aHR0cHM6Ly9vbGxhbWEuY29tL3NlYXJjaA%3D%3D。
这一步可能需要一些时间,请等待下载完成。
ollama pull deepseek-r1:1.5b
pulling manifest
pulling aabd4debf0c8... 100% ▕████████████████▏ 1.1 GB
pulling 369ca498f347... 100% ▕████████████████▏ 387 B
pulling 6e4c38e1172f... 100% ▕████████████████▏ 1.1 KB
pulling f4d24e9138dd... 100% ▕████████████████▏ 148 B
pulling a85fe2a2e58e... 100% ▕████████████████▏ 487 B
verifying sha256 digest
writing manifest
success
下载模型后,您可以使用以下命令运行它:
ollama run deepseek-r1:1.5b
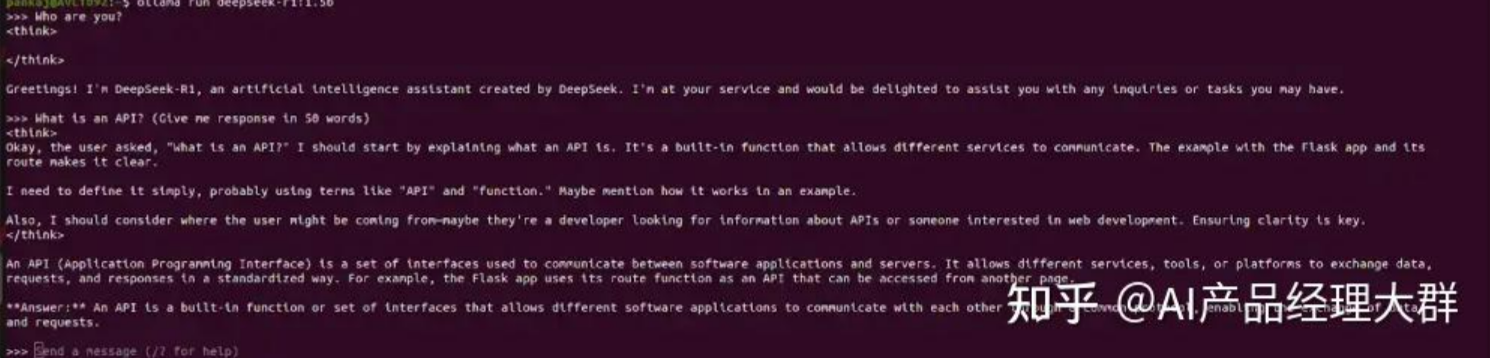
现在,该模型可以在本地计算机上使用,并顺利回答了我的问题。

今天这个教程颜值相当高,从色偏的角度,教同学们把皮肤修得白皙好看,特别适合妹子或有妹子的男生,附上高...
去看看>>
“《連城》作品系列展出的各張攝影作品各具主題,但離不開中心主旨:琴澳關係。”鏡頭中的95後澳門青年攝...
去看看>>
每个插画师的创作方式都不一样,有人喜欢将画面构思好了再动笔,而我比较喜欢从一堆杂乱的色彩和线条中理清...
去看看>>
北京青年美術雙年展是立足北京、輻射京津冀、面向全國的綜合性青年藝術展示、學術交流、藝術家培養平台,是...
去看看>>
官宏滔摄影作品、吴析夏三维装置作品展
去看看>>
随着时代更迭、科技创新 人们的媒体生活不再平面 如今,我们以多面立体的生活方式 感受着这个瞬息万变的...
去看看>>
这是一个忙碌而躁动的时代,我们每天都在接受海量信息的洗礼,而手机是我们接受信息冲击的最前线,每天都有...
去看看>>
先阅读【开发工具】部分,确保开发环境可以编写代码并运行。然后学习【数据分析】或【Python小游戏开...
去看看>>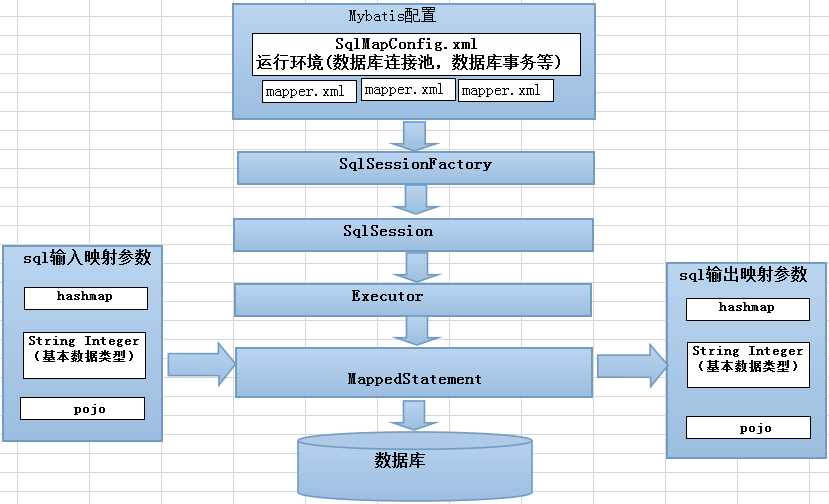
Mybatis工作流程可以大致分为四个步骤:加载配置并初始化、接收调用请求、处理操作请求 触发条件:...
去看看>>
连城琴澳摄影/装置艺术展 圆满举办
去看看>>