
2025年1月27日,英伟达股价大跌17%,市值缩水6000亿美元,创美史单日最大跌幅。相关公司如博通、AMD、微软等均受影响。国内媒体将此归咎于DeepSeek的崛起,引发对半导体企业估值的担忧。
DeepSeek的V3/R1模型究竟是怎么样的呢?有什么创新
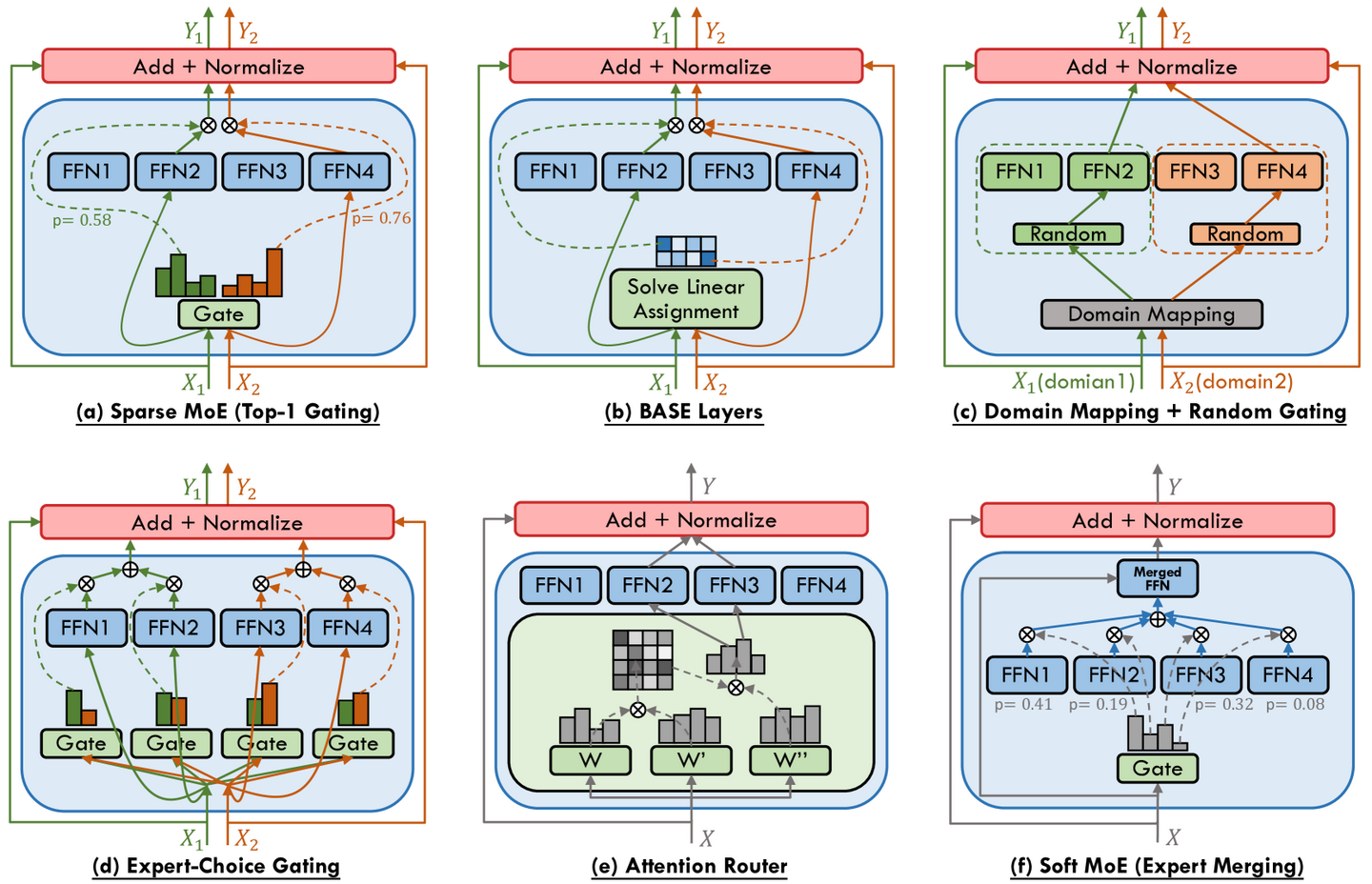
MoE架构指通过组合多个专家模型来提升深度学习模型的性能和效率,其核心是只激活部分专家模型处理输入数据,以减少计算量并加快训练推理速度。
MoE概念早在1991年就提出了,但其在大模型领域的应用确有诸多困难,如受限于训练收敛困难。
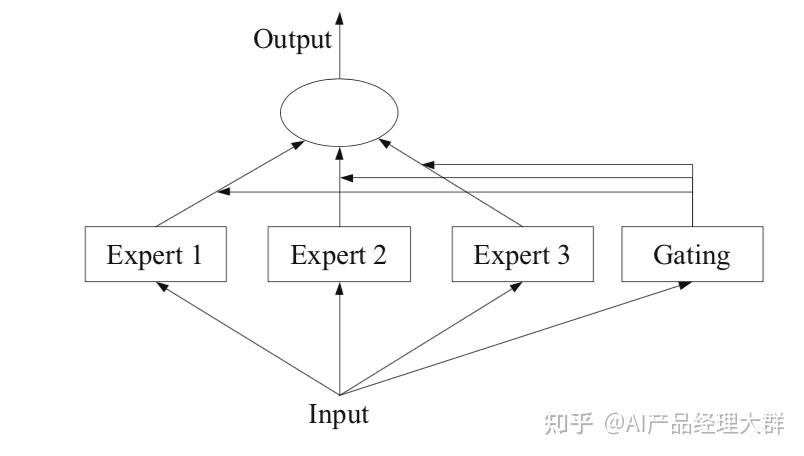
MoE可以理解为是一种路由形式的网络层结构, 网络层主要包括三部分:
进入Transformer时代后,Google(2020年)在Transformer上做MoE的经典设计,主要包括Transformer MoE层设计和辅助负载均衡损失。
Transformer MoE层:用MoE层替换Transformer的FFN层:对于一个token 分别通过门控网络和专家网络计算门控值和专家输出,然后用门控值加权多个专家输出来的结果。具体如下:
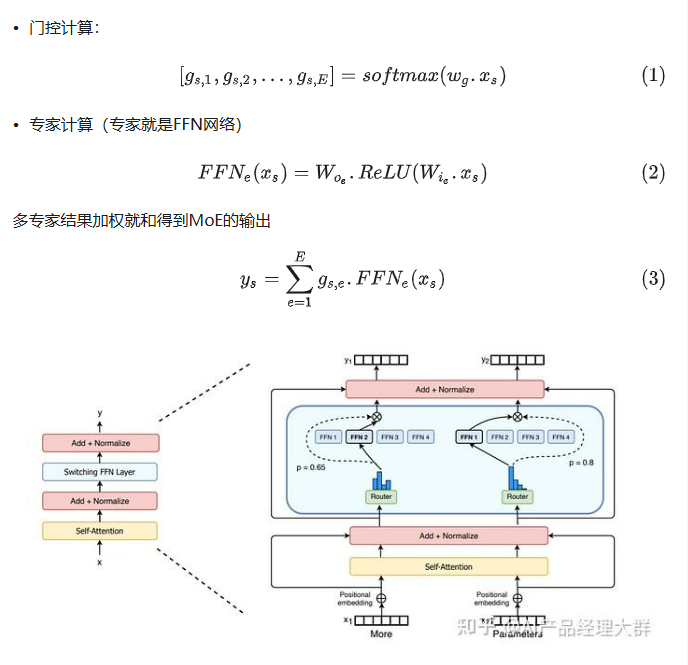


下面先分别分析V3和R1的架构特征。
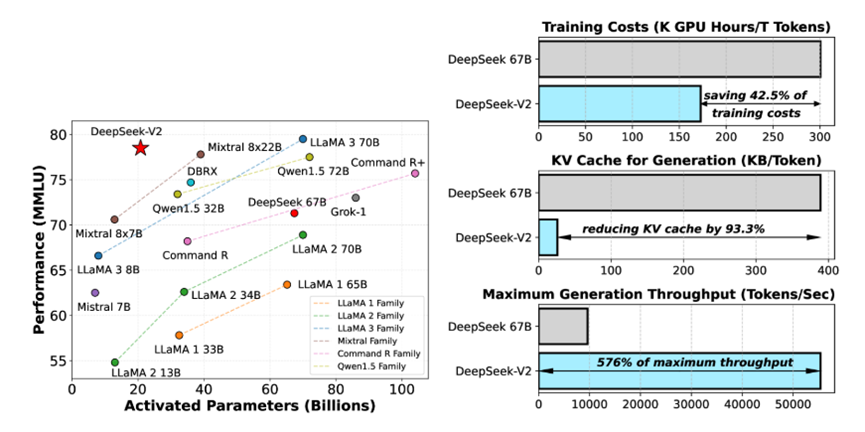
| DeepSeek-V3是一个拥有6710亿参数的混合专家(MoE)语言模型,每处理一个Token大约激活370亿参数,与GPT-4的参数量相当。该模型采用了多头潜注意力(MLA)和DeepSeekMoE架构等创新技术,并采用了无需辅助损失的负载平衡策略,在14.8万亿Token的数据上训练,特别擅长代码生成和分析任务。 MLA和DeepSeekMoE是DeepSeek-V3及其前身R1模型提高计算效率、减少算力浪费的关键技术。MLA通过改进传统多头注意力机制,实现了2-4倍的计算效率提升,而DeepSeekMoE对传统MoE架构的改进则带来了超过4倍的计算效率提升。这些技术的应用使得DeepSeek-V3在保持大规模参数优势的同时,显著提高了计算效率。 |
|---|
在深度学习领域,注意力机制已经成为主流,但传统的多头注意力(MHA)中的键值(KV)缓存机制对计算效率构成了挑战。在过去的模型中,缩小KV缓存大小并提升性能的问题并未得到有效解决。
DeepSeek模型通过引入多头潜注意力(MLA)机制,利用低秩键值联合压缩技术,显著减小了KV缓存的大小,同时提高了计算效率。低秩近似在MLA中的应用为大模型计算开辟了新的路径。
未来,可能会有更多精准高效的方法来实现潜空间表征,进一步优化大模型的性能。
随着大模型架构的发展,Prefill和KV Cache容量瓶颈问题正在被新架构逐步克服,大型KV缓存的问题正在逐渐成为过去。
为了使MoE架构更好地融入大模型体系并克服传统MoE模型的训练难题,DeepSeek采用了细粒度专家+通才专家的思路。这种思路不再依赖于少数大型专家结构,而是使用大量极小的专家结构。这种方法的核心在于将知识空间进行离散细化,以更好地逼近连续的多维知识空间。
无辅助损失的负载平衡策略能够在不依赖辅助损失函数的情况下平衡计算/训练负载,从而提高训练稳定性。
基于这些关键改进,DeepSeek-V3实现了更高的训练效率,与性能类似的Llama 3.1 405B模型相比,减少了大约10倍的训练计算量。
DeepSeek-R1的模型架构来自于V3,甚至可以说R1是具有推理(Reasoning)能力的V3。
DeepSeek-R1系列模型不仅包括主要的R1模型,还包括其初始阶段模型DeepSeek-R1-Zero以及基于R1蒸馏的较小模型。下面主要讨论R1-Zero和R1两个模型。
1.2.1 DeepSeek-R1-Zero
DeepSeek-R1-Zero模型的最大特点是它完全通过强化学习进行训练,而不依赖于有监督微调。这种训练方法利用了各种思维链(CoT,Chain of Thought)数据,尤其是Long CoT数据,来激发模型的推理能力。
DeepSeek-R1-Zero是一个通过大规模强化学习(RL)训练的独特模型,它展现了以下特点:
推理能力:R1-Zero模型能够进行自我验证、反思和长链思维推理,这些能力在推理任务上的表现甚至略微超过了R1模型。
概念区分:需要明确区分“推理(Reasoning)”和“推断(Inference)”两个概念。推理是一个涉及逻辑和分析的思考过程,而推断则更多是基于算法或模型的计算过程。
尽管R1-Zero在推理能力上表现出色,但它也存在一些局限性,特别是在输出可读性和语言一致性方面。这些问题,如可读性差和语言混合,需要进一步解决。
R1-Zero的成功标志着大模型的推理能力可以通过强化学习单独训练得到,这一发现的价值可能超过了R1模型本身。在R1-Zero的进一步发展过程中,有潜力构建出更适合推理的混合语言IR(信息检索)系统,以及更高效的推演体系。这为未来的模型发展提供了新的方向和可能性。
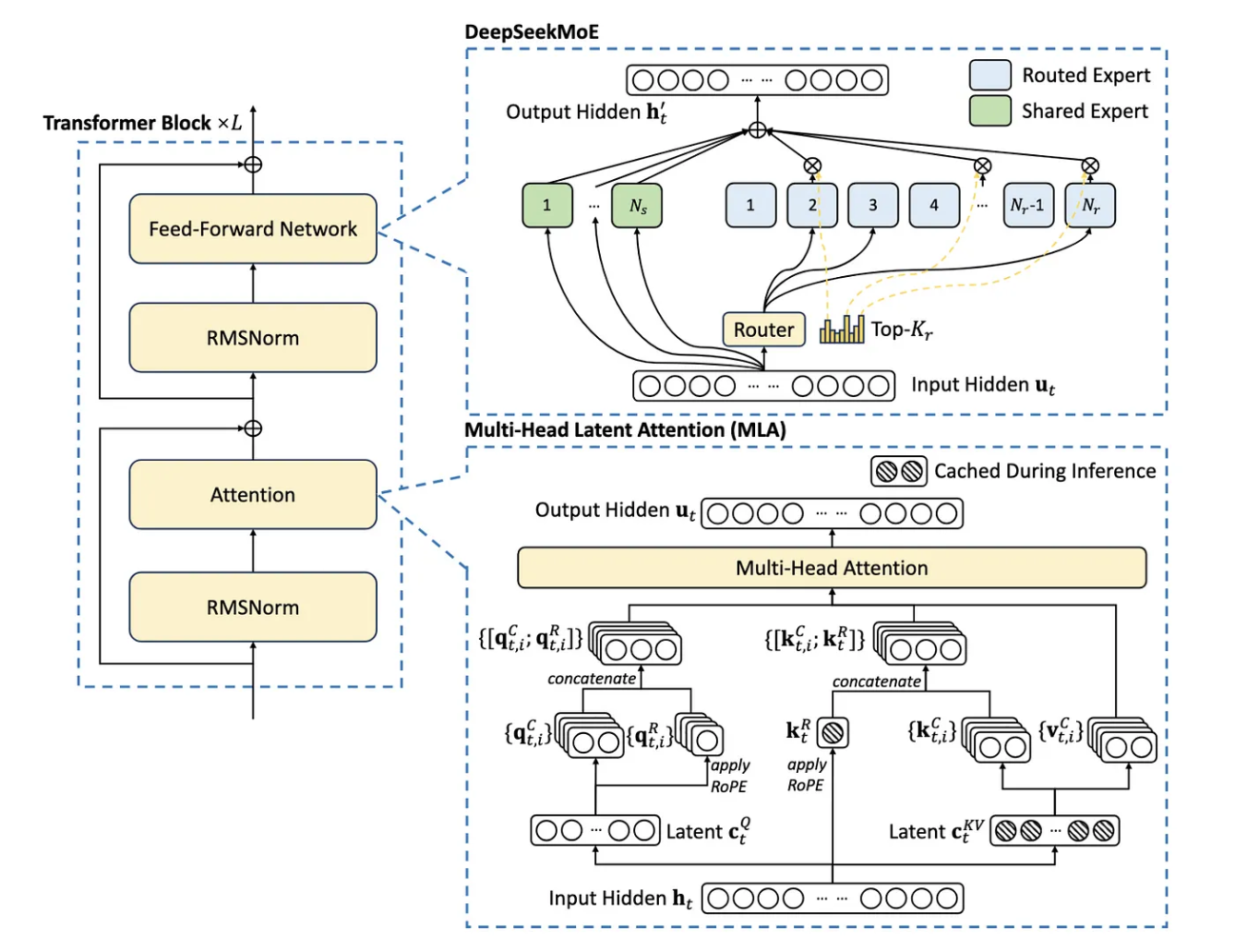
从KV Cache(KV缓存)说起在传统的Transformer模型中,推理过程中需要重新计算所有过去Token的上下文,这通常涉及重复计算,导致效率低下。为了提高效率,常用的方法是缓存过去Token的内部状态,特别是注意力机制中的键(Key)和值(Value)向量,即KV缓存。
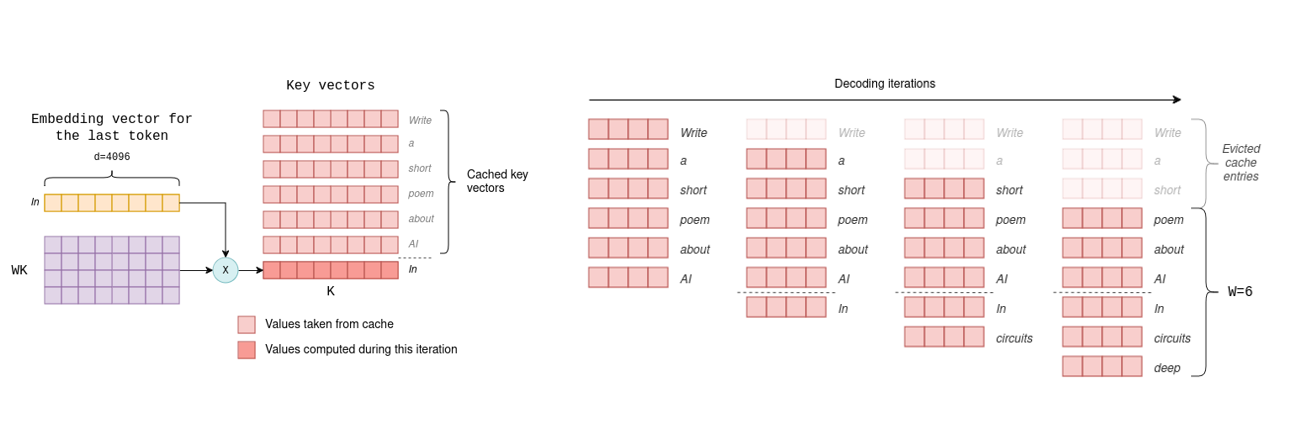
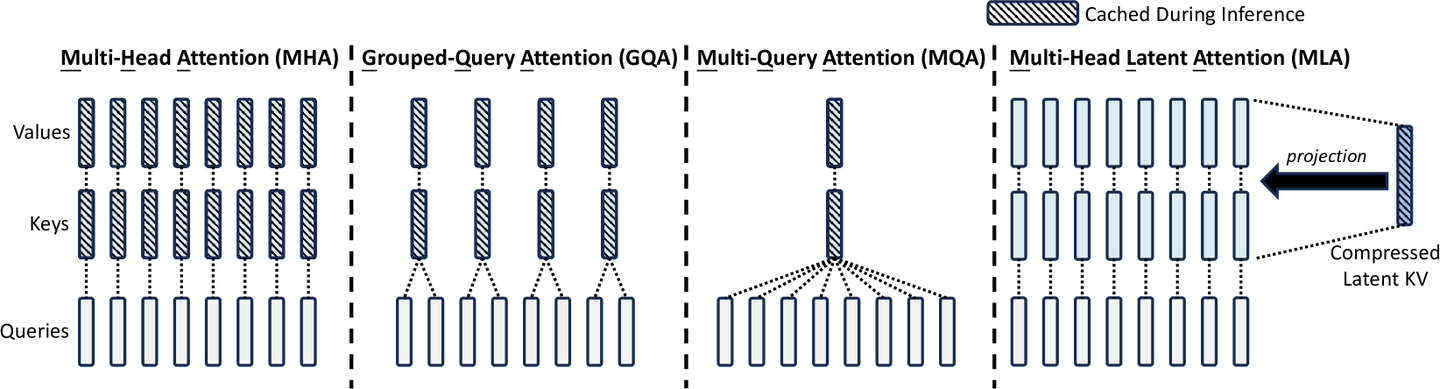
MLA的原理与优势DeepSeek采用的Multi-Head Latent Attention(MLA)技术显著减少了KV缓存的大小,从而降低了计算成本。MLA通过对KV矩阵进行有损压缩,将其转换为低秩形式,即两个较小矩阵的乘积,在推断时仅缓存这些潜向量。这种方法比分组查询和多查询注意力更为有效,减少了KV缓存的同时保持了性能。。
MLA的创新MLA是一项基于对注意力机制深度理解的创新技术。它的开发得益于DeepSeek团队在量化金融和FPGA底层优化方面的背景。MLA的出现不仅降低了KV缓存和训练成本,还为未来的注意力机制优化提供了新的方向。
MLA之后可能会有QMLA(量化MLA)或CMLA(压缩MLA)等进一步优化KV缓存的方法出现。甚至可能发展出超越现有Attention模式的新技术,从而推动Transformer架构经历重大的变革。
MoE与Dense模型的混战 当前,大模型架构主要分为Dense(稠密)和MoE(混合专家)两种。
Dense模型在深度学习中指的是所有神经元都参与计算的网络结构,这种结构能够充分利用数据特征,并通过参数共享减少计算量和过拟合风险。Dense模型可以看作是只有一个专家的MoE模型。在大模型领域,Dense模型和MoE模型各有优势,MoE尚无法完全取代Dense模型的应用。
Dense模型与MoE模型对比:
MoE模型通过专家路由来引导数据流向不同的专家模块,但这种方法引入的非连续门控函数对梯度计算不友好,可能导致路由崩溃。传统的解决方法是使用辅助损失来强制平衡路由,但这会损害MoE模型的性能。
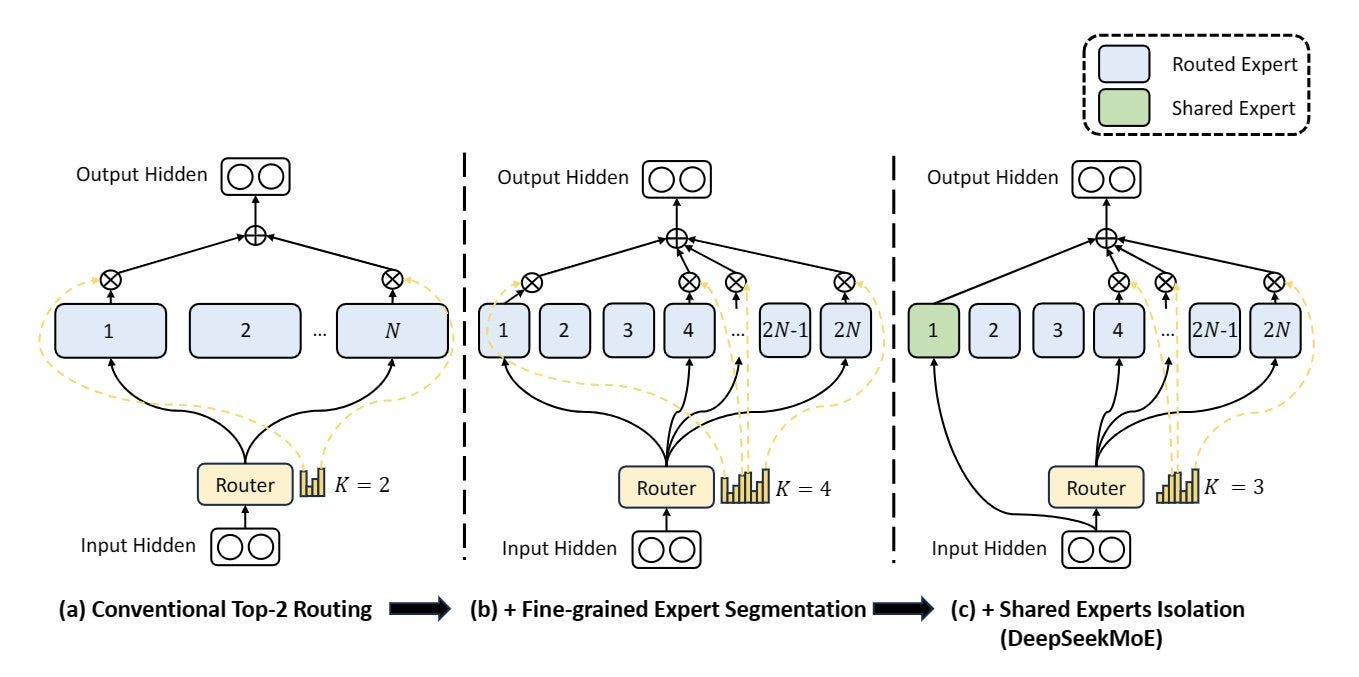
无辅助损耗负载均衡 DeepSeek采用了“增加共享专家+无辅助损耗负载平衡”的方法来解决路由崩溃问题。DeepSeek将专家分为共享专家和路由专家,共享专家始终被路由,而路由专家则通过动态调整偏差项来确保负载均衡,无需辅助损失。
无辅助损耗负载均衡方法通过监控和调整偏差项来确保每个专家在训练中得到合理的激活次数,从而提高了DeepSeek-V3在训练过程中的性能。
MoE架构与Dense架构一直在共生发展。DeepSeek R1的推出推动了开源MoE大模型的发展,但MoE模型并不总是比Dense模型更适合所有场景。
MoE模型的应用一般与领域高度相关,且总拥有成本(TOC)也是一个重要因素。不同的应用场景对Dense和MoE模型的需求不同:
目前,只有To C云计算场景(如OpenAI的网页版服务)更适合使用MoE这种多专家模型架构。因此,MoE可以与Dense模型共存,我们可以根据不同的应用需求选择合适的架构。
DeepSeek的优势在于其专用的训练框架和软硬件协同优化,提升了训练速度和效率。其核心特点包括:1)采用FP8混合精度训练,加速训练并降低GPU内存使用;2)DualPipe算法提高流水线并行效率,减少通信开销;3)优化跨节点All-to-All通信和显存使用,无需张量并行即可训练DeepSeek-V3。这些能力是DeepSeek领先国内其他大模型团队的关键。
V3模型训练采用DeepSeek自研的HAI-LLM框架,该框架高效轻量,支持多种并行策略。以下是并行模式的简要对比和DeepSeek的具体优化措施:
| 缩写 | 简介 | DeepSeek优化 |
|---|---|---|
| TP | 张量并行 | 集成NVLink Bridge,提升带宽至600GB/s |
| PP | 流水线并行 | 优化数据排队,实现高效GPU通信 |
| FSDP | 全共享数据并行 | 重叠通信与计算,减少训练时间 |
| DP | 数据并行 | PCIe工程优化,提升性能 |
| EP | 专家并行 | PCIe工程优化,提升性能 |
V3模型应用了16路PP、64路EP跨8节点,以及ZeRO-1 DP,实现高效训练。
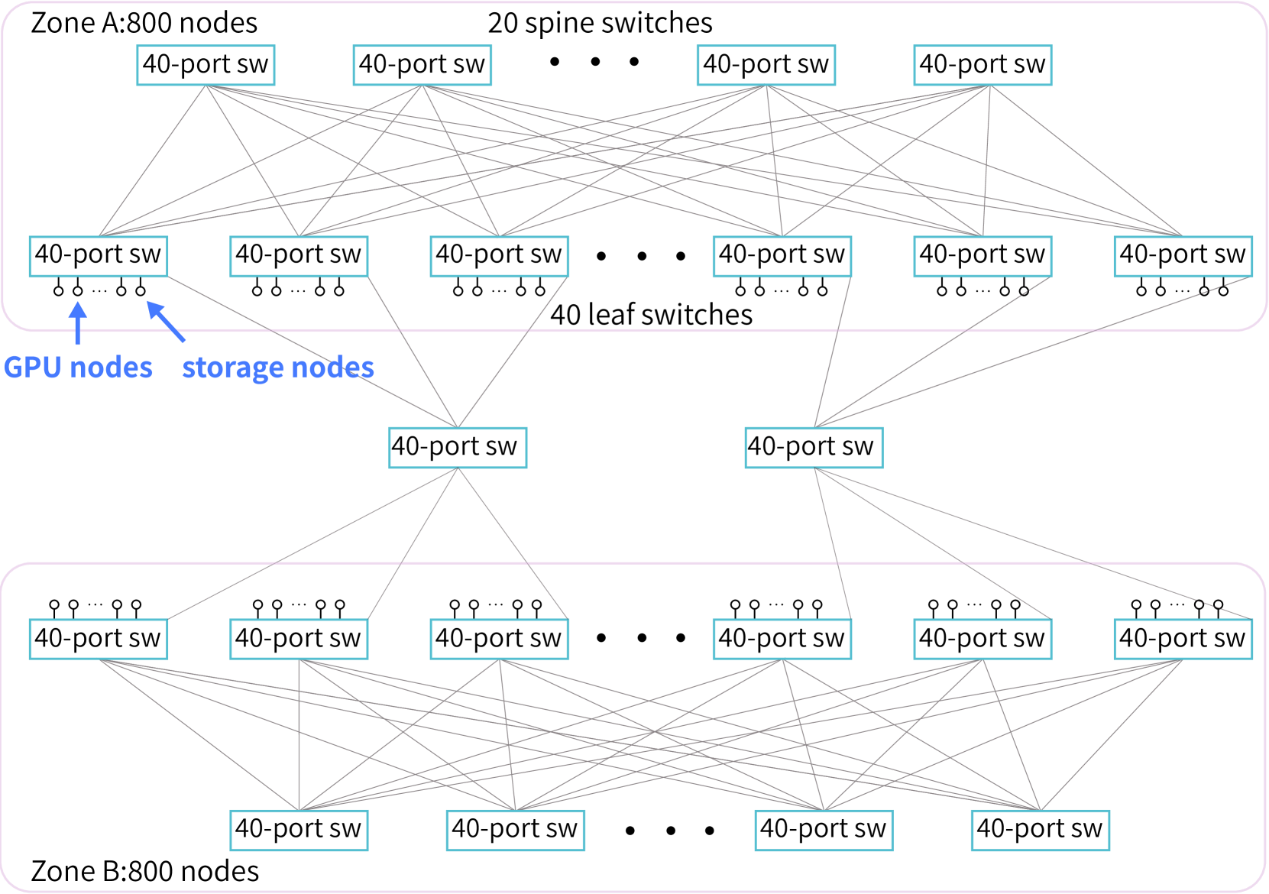
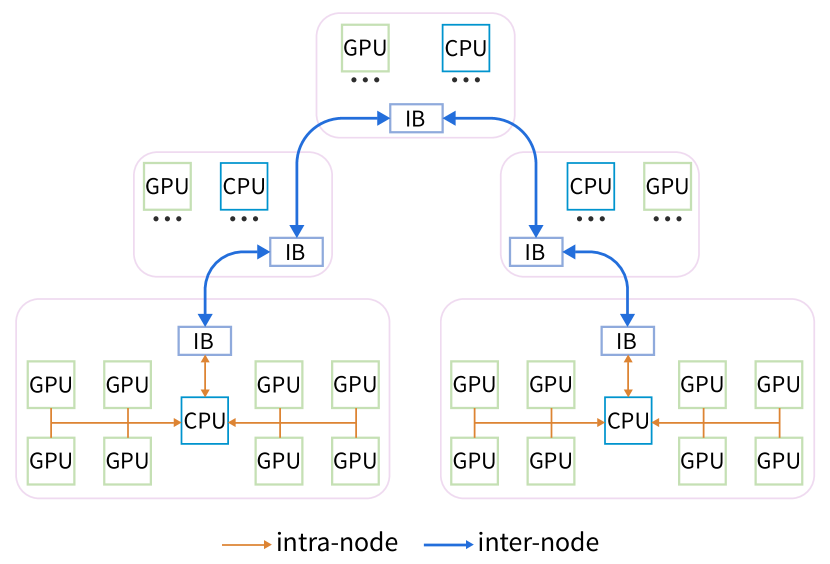
为了配合HAI-LLM训练框架(软件),DeepSeek采用两层Fat-Tree拓扑+ InfiniBand (IB)作为集群架构(硬件)。这一集群架构的核心思路是减少互连层次,降低训练的综合成本。相对DGX-A100 的标准万卡集群三层Fat-Tree的1320个交换机,DeepSeek的同规模集群仅仅需要122台交换机,至少节省了40%的互连成本。
DeepSeek开发了HFReduce优化硬件架构,特别针对无NVLink的方案。HFReduce先在节点内执行reduce,再通过CPU进行节点间allreduce,并将数据传输到GPU。此优化体现了DeepSeek对硬件互连的深入理解。此外,DeepSeek还开发了NVLink版的HFReduce,它先在GPU间通过NVLink执行reduce,再由CPU处理,最后通过NVLink allgather返回数据至GPU。
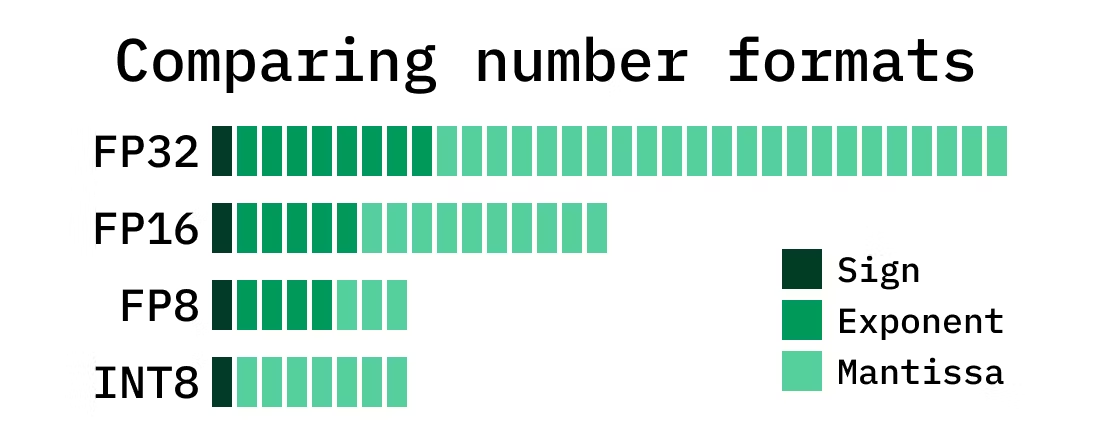
FP8与其他数据格式空间对比:FP8仅占FP32的1/4空间,提升计算速度,降低存储消耗,但精度较低,训练风险增加。
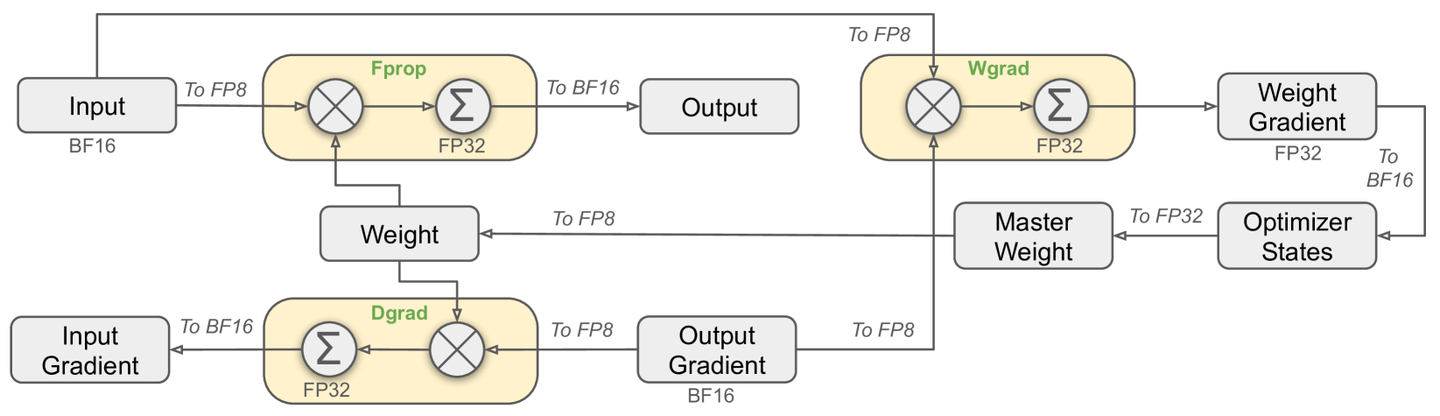
DeepSeek-V3采用FP8训练框架以减少显存使用,优化措施包括:1)细粒度量化:数据分组缩放,保持精度。2)在线量化:实时计算缩放因子,提高转换精度。3)提高累加精度:中间结果用FP32存储,减少误差累积。4)低精度/混合精度存储与通信:FP8缓存处理激活,关键组件保持高精度。
4)低精度/混合精度存储与通信
为了进一步减少 MoE 训练中的显存和通信开销,该框架基于FP8 进行数据/参数缓存和处理激活,以节省显存与缓存空间并提升性能,并在 BF16(16位浮点数)中存储低精度优化器状态。
该框架中以下组件保持原始精度(例如 BF16 或 FP32):嵌入模块、MoE 门控模块、归一化算子和注意力算子,以确保模型的动态稳定训练。为保证数值稳定性,以高精度存储主要权重、权重梯度和优化器状态。
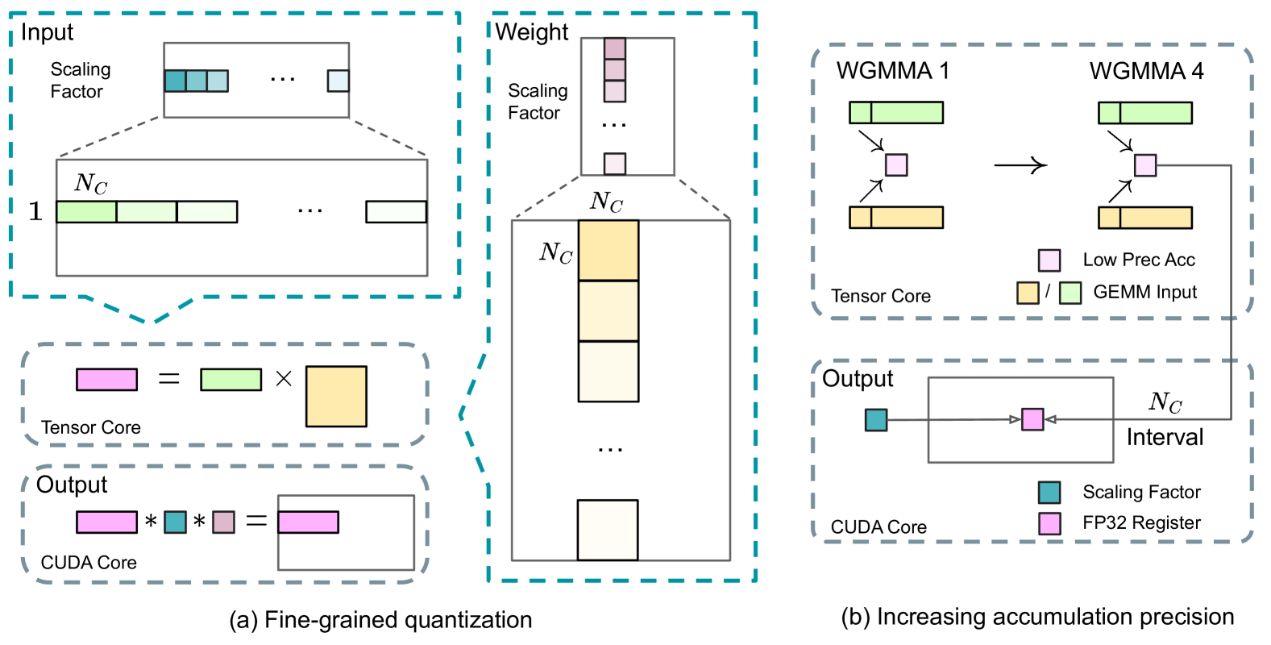
DeepSeek团队在FP8框架上的精细优化展现了其对GPU架构和训练误差的深刻理解,体现了强大的技术和工程能力。
V3/R1训练框架采用DualPipe算法提升流水线并行效率,优势包括减少流水线气泡、提高信道效率,以及计算通信重叠,解决了跨节点专家并行的通信问题,并具有良好的扩展性。DualPipe将数据块分为注意力、全到全分发、MLP和全到全组合四部分,优化前向和后向块的通信与计算,实现双向流水线调度,提升使用率。

V3/R1的训练框架还定制了高效的跨节点All-to-All通信内核,以充分利用IB 和 NVLink 带宽,并节约流式多处理器 (SM,(Stream Multiprocessor)。DeepSeek还优化了显存分配,以在不使用或少使用张量并行 (TP) 的情况下训练 V3/R1。
为了保证 DualPipe的计算性能不被通信影响,DeepSeek定制了高效的跨节点 All-to-All 通信内核(包括 dispatching 和 combining),以节省专用于通信的 SM数量。
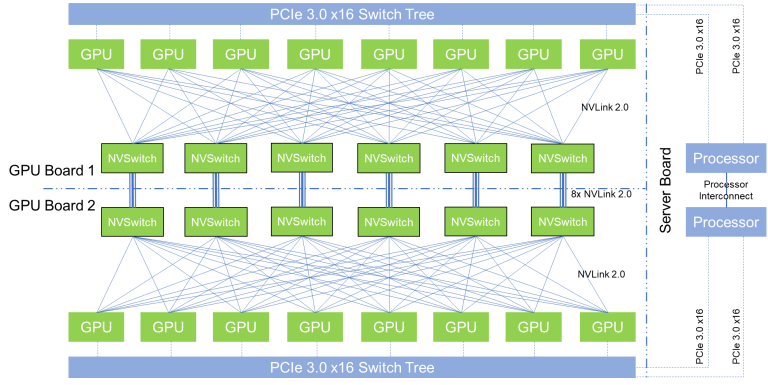
DeepSeek优化了基于NVSwitch的All-to-All通信结构,以软硬件协同的方式设计通信内核。在集群中,跨节点通信通过IB完成,节点内通信则利用NVLink的高带宽。为最大化IB和NVLink的性能,DeepSeek限制了每个Token的分发最多经过4个节点,减少IB流量限制的影响,并通过IB和NVLink的通信重叠,提高了专家选择效率。
在V3/R1模型中,虽然只选择了8个专家,但该架构可扩展到最多13个专家。DeepSeek还采用了warp专用化技术,将SM划分为通信信道,动态调整warp数量以处理不同的通信任务。通信和计算流重叠,且通过定制PTX指令调整通信块大小,减少了对缓存的占用和对其他SM的干扰。这种优化提高了通信效率,降低了延迟。
为了减少训练期间的内存占用,V3/R1还采用了以下技术节省显存:
DeepSeek采用的显存节省技术(来源:中存算)
| 技术 | 方法说明 | 优势 |
|---|---|---|
| RMSNorm 和MLA Up-Projection 的重新计算 | 在反向传播期间重新计算所有MSNorm操作和MLA Up-Projection,无需持久存储其输出激活 | 以算代存,充分利用GPU内算力充沛但缓存不足的特点 |
| 在CPU内存中保存指数平均数指标(EMA) | 在CPU 内存中保存EMA,并在每个训练步骤后异步更新 | 把EMA从GPU显存占用改为CPU内存占用,释放动态存储空间 |
| 在多标记预测(MTP)中共享嵌入和输出头 | 使用DualPipe 策略,将模型最浅的层(包括嵌入层)和最深的层(包括输出头)部署在相同的PP等级上 | 允许MTP模块和主模型之间物理共享参数、梯度、嵌入和输出头,提升显存效率 |
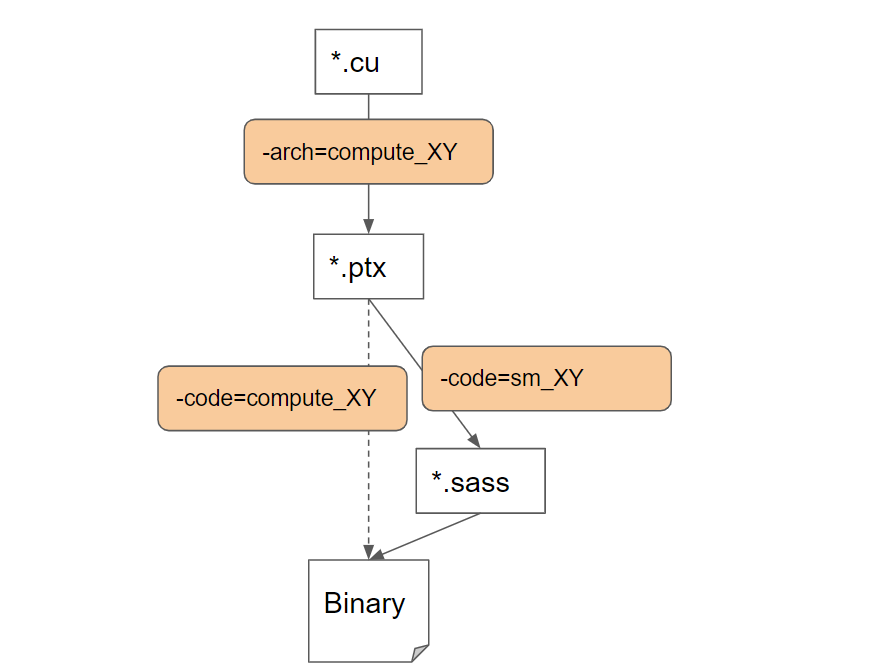
CUDA与PTX、SASS的关系可以这样描述:CUDA是高级编程语言,PTX是其中间表示,类似于汇编语言,而SASS是更低级的、特定于GPU型号的指令集。使用PTX并不打破CUDA的生态,而是为了更精细的硬件优化。
如图所示,PTX是CUDA生态的基石,而DeepSeek使用PTX,就像是在C语言中嵌入汇编,旨在提升性能,而非取代CUDA。这并不意味着打破了CUDA的地位,而是展现了对其生态深度的利用。
DeepSeek的R1是以V3为基础构建的(冷启动)。如果想深入理解R1的训练,就要先看V3的训练流程。V3的训练包括预训练(含基础预训练和上下文长度扩展)、后训练三个阶段。
在预训练阶段后,对DeepSeek-V3 进行了两次上下文长度扩展,第一阶段将最大上下文长度扩展到32K,第二阶段进一步扩展到128K。然后在 DeepSeek-V3的基础模型上进行包括有监督精调 (SFT) 和强化学习(RL)在内的后训练,使其更贴近人类的偏好。
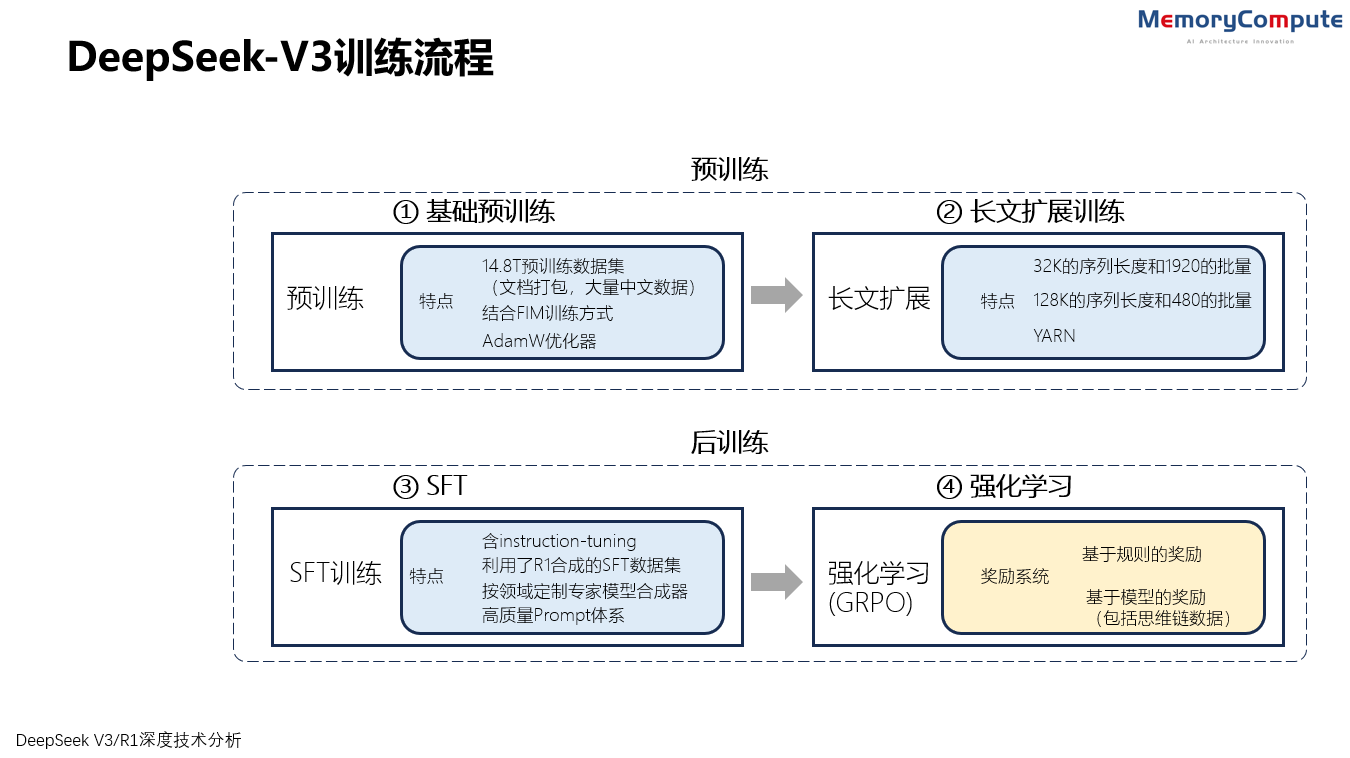
DeepSeek-V3训练流程(来源:中存算)
DeepSeek-V3 模型拥有671B参数,每个Token处理时激活37B参数。在专家路由机制中,每个Token激活8个专家,并通过限制每个Token最多发送到4个节点,有效减少了通信资源的消耗。多Token预测(MTP)的深度设置为1,意味着除了预测下一个Token外,每个Token还会额外预测一个Token。
在14.8T的预训练数据集上,V3采取了以下策略优化: 1)提升数学和编程样本的比例,优化预训练语料库,增强模型推理能力。 2)整合更多中文数据,特别是基于中国互联网的语料库,使V3能够熟练运用中文网络梗。 3)扩大多语言覆盖范围,不仅限于英文和中文。 4)优化数据处理和过滤算法,在保持语料库多样性的同时,最大程度减少信息冗余,并过滤掉争议内容,降低数据偏差。 5)通过文档打包技术,减少短文本块训练的浪费,且训练过程中未采用交叉样本注意力屏蔽。
高质量的数据结构和投喂顺序对大模型性能至关重要,但DeepSeek未公开具体的预训练数据构建方法。
在基础预训练后,V3使用YARN技术将上下文长度,按照两阶段训练扩展到128K,每个阶段包括1000步。在第一阶段,使用32K的序列长度和1920的批量来执行1000步训练。在第二阶段,采用128K的序列长度和480个序列的批量大小执行1000步训练。
V3的有监督精调(SFT)涉及: 1)梳理1.5M实例的指令精调数据集,定制多领域数据合成。 2)利用DeepSeek-R1合成推理相关SFT数据,实现模型互促训练。 3)为特定领域构建专家模型,通过复合SFT和强化学习生成两种SFT样本。 4)建立高质量提示体系,结合R1数据,通过强化学习增强模型能力。 5)非推理数据由DeepSeek-V2.5生成,经人工验证。
V3强化学习采用奖励模型和GRPO策略: 1)基于规则的奖励模型确保生成可靠性。 2)基于模型的奖励模型处理非收敛问题,降低奖励破解风险。
GRPO策略简化训练,无需显式价值网络,提高效率。流程包括采样、奖励计算、归一化、优势函数计算和策略模型更新。
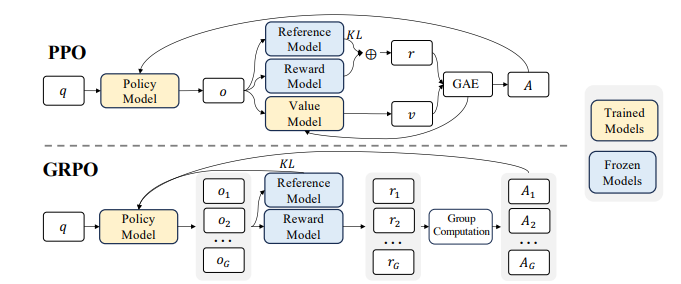
DeepSeek-R1基于DeepSeek-V3的混合专家架构,采用专家并行机制,确保输入时仅部分参数活跃。R1-Zero,作为无SFT版本,以DeepSeek-V3-Base为基础,通过GRPO强化学习提升推理性能,训练奖励基于准确度和格式。
R1-Zero的训练重要性: 1)避免SFT对高质量标注数据的依赖,减少成本和偏差。 2)可能超越人类思维上限,实现超级推理能力。 3)允许模型采用非自然语言方法“思考”,拓展逻辑推理能力。
R1-Zero的奖励系统包括准确度和格式奖励,评估响应的正确性和格式。
与GPT-4相比,R1-Zero在AIME 2024推理测试中性能显著提升,验证了无SFT推理训练的有效性。

DeepSeek-R1 的训练过程分为4个阶段,包括使用数千高质量CoT示例进行SFT的冷启动,面向推理的强化学习,通过拒绝抽样的SFT,面向全场景任务的强化学习与对齐。
两个SFT阶段进行推理和非推理能力的能力植入,两个强化学习阶段旨在泛化学习推理模式并与人类偏好保持一致。
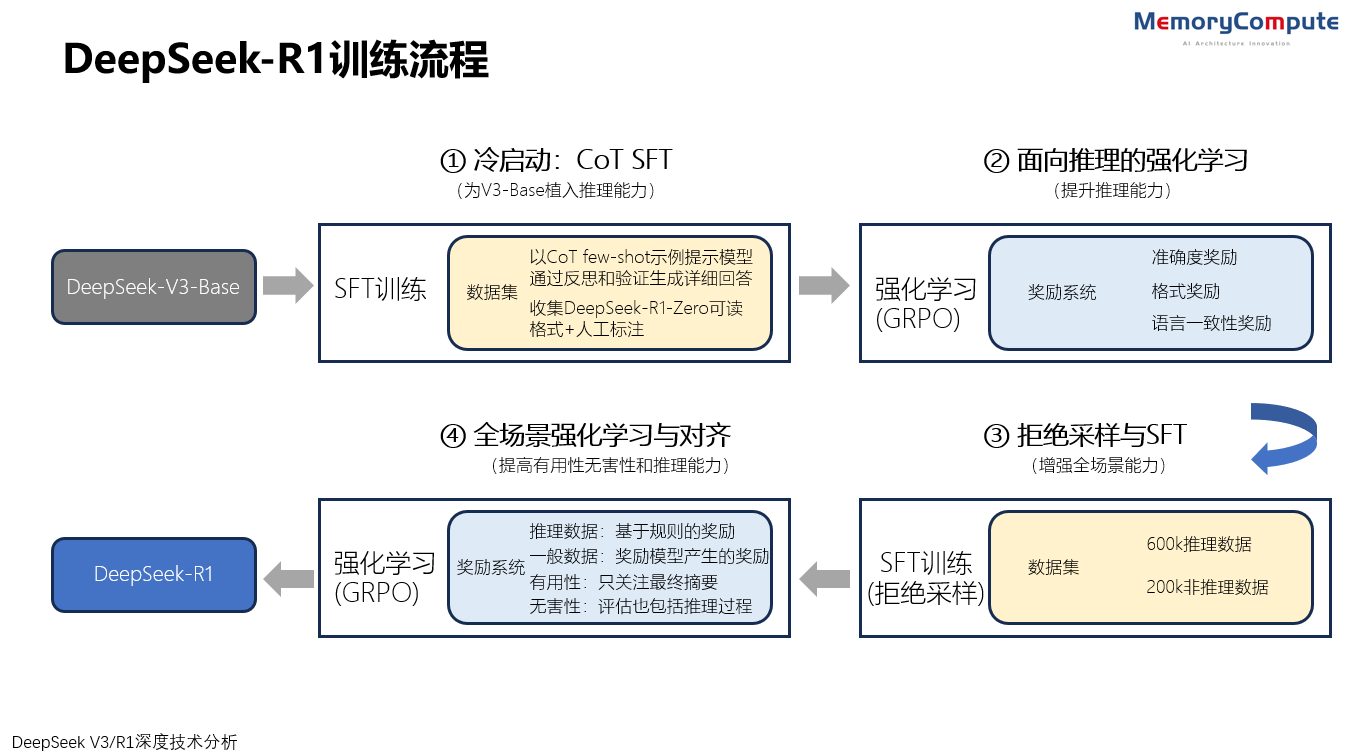
DeepSeek-R1训练流程(来源:中存算)
与R1-Zero不同,R1首先基于DeepSeek-V3-Base进行有监督精调(SFT),以克服强化学习的早期不稳定。DeekSeek认为这种基于人类先验知识冷启动并进行迭代训练的方式更适合推理模型。
由于这一训练阶段主要采用CoT数据,将其称为CoT SFT。
为构建少量的长CoT数据,DeepSeek探索了几种合成方法:使用长CoT 的few-shot提示作为示例,直接提示模型通过反思和验证生成详细回答,以可读格式收集DeepSeek-R1-Zero 输出,并通过人工标注员的后处理来完善结果。在此步骤中收集了数千个冷启动样本以进行精调。
其中可读模式指为每个回答在末尾包含一个摘要,并过滤掉不易阅读的部分。其输出格式为 |special_token|<reasoning_process>|special_token|<summary>。
在基于冷启动数据对V3-Base 精调后,采用与R1-Zero相当的强化学习训练流程,基于GRPO进行强化学习,根据准确度和格式进行训练奖励。为了解决语言混杂问题,还在强化学习训练中引入了语言一致性奖励,该奖励以CoT中目标语言单词的比例计算。
此阶段主要提升模型的推理(Reasoning)性能,特别是在编码、数学、科学和逻辑推理等推理密集型任务,这些任务涉及定义明确且解决方案明确的问题。
这是另一个使用标记数据的有监督精调 (SFT)训练阶段,分批进行了两个epoch的精调,样本量为800k。800k中包括600k推理数据和200k非推理数据。
与主要侧重于推理的冷启动数据不同,此阶段结合了来自其他领域的数据,以增强模型在写作、角色扮演和其他通用任务中的能力。
拒绝采样(Rejection Sampling)提供了一种桥梁,使用易于采样的分布来近似训练真正感兴趣的复杂分布。目标响应(ground-truth)从一组生成的回答经过拒绝采样生成,其分数由奖励系统确定。
| 拒绝采样(Rejection Sampling)是一种蒙特卡洛方法,和重要性采样一样,都是在原始分布难以采样时,用一个易于采样的建议分布进行采样,通过拒绝原始分布之外的采样数据来获得采样结果。拒绝采样只是为了解决目标分布采样困难问题,该方法需要原始分布是已知的。 |
|---|
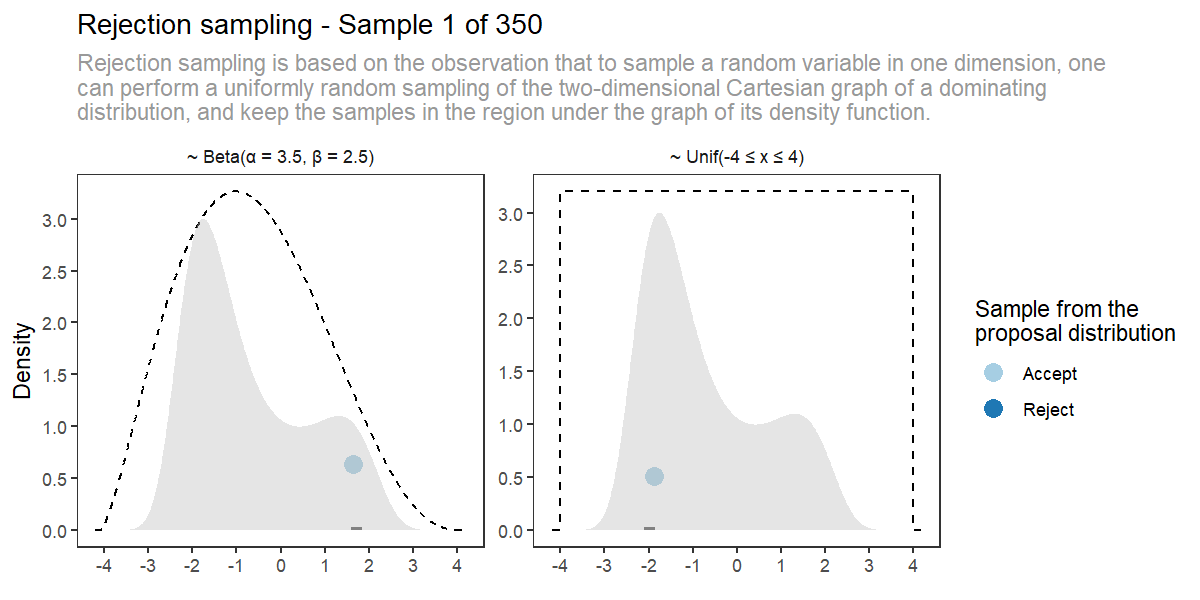
拒绝采样示意
600k推理数据的生成:
1)通过从上一轮强化学习训练的检查点进行拒绝抽样,整理推理提示并生成推理轨迹(Reasoning Trajectories)。
2)除基于规则奖励进行评估的数据外,还包括了基于奖励模型的V3判断生成数据。
3)过滤掉了混合语言、长段落和代码块的思路链数据。
4)对于每个提示(Prompt),会生成多个回答,然后并仅保留正确的响应。
200k非推理数据的生成(如写作、事实问答、自我认知和翻译等):
1)采用DeepSeek-V3流程并复用V3 的部分 SFT 数据集。
2)可调用V3生成潜在的思路链,再通过提示回答。
3)对于更简单的查询(例如“你好”),不提供CoT回答。
最后,再次进行面向全场景的强化学习和人类偏好对齐,以提高模型的有用性和无害性,并完善推理能力。此阶段还整合了来自不同管道的数据,将奖励信号与不同的提示分布相结合。
1)使用奖励信号和多种提示分布(Diverse Prompt Distributions)的组合来训练模型。
2)对于推理数据,利用基于规则的奖励来指导数学、代码和逻辑推理领域的训练过程。
3)对于一般数据,采用奖励模型来捕捉复杂微妙场景中的人类偏好。即参考DeepSeek-V3 管训练流程,采用类似的偏好对和训练提示分布。
4)对于有用性,只关注最终摘要,以确保重点响应对用户的实用性和相关性,最大限度减少对底层推理过程的干扰。
5)对于无害性,评估模型的整个响应,包括推理过程和摘要,以识别和减轻生成过程中可能出现的潜在风险、偏见或有害内容。
至此已完成R1的完整训练过程,获得了具备全场景推理能力的通用MoE模型,上下文长度均为128K。
| Model | #Total Params | #Activated Params | Context Length |
|---|---|---|---|
| DeepSeek-R1-Zero | 671B | 37B | 128K |
| DeepSeek-R1 | 671B | 37B | 128K |
尽管MoE架构有各种优点,特别是在通用的to C领域具备低成本的优势。但是MoE的架构特点使得其可能不太适用于专业应用场景(例如单一专家场景)和资源限制场景(例如端侧推理)。
| 蒸馏是将复杂的大型神经网络压缩为更小、更简单的神经网络,同时尽可能多的保留结果模型的性能的过程。此过程涉及训练较小的“学生“神经网络,通过其预测或内部表示的精调来学习模拟更大、更复杂的“教师”网络的行为。 |
|---|
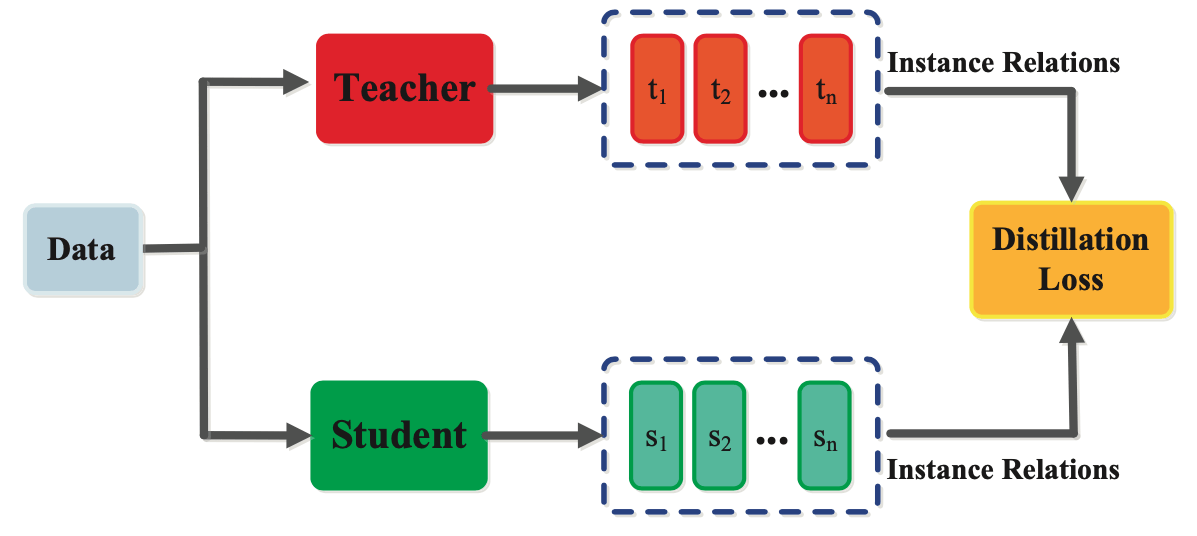
模型蒸馏方法(来源:互联网)
为了能够将推理能力迁移到MoE架构不适合的场景,DeepSeek选择Llama和Qwen系列开源大模型进行蒸馏,使相应的Dense模型也能获得推理能力。与使用强化学习相比,直接SFT更适合较小的大模型,蒸馏完成的Dense模型推理能力明显好于原开源模型。
DeepSeek-R1-Distill模型(来源:DeepSeek)
| Model | Base Model |
|---|---|
| DeepSeek-R1-Distill-Qwen-1.5B | Qwen2.5-Math-1.5B |
| DeepSeek-R1-Distill-Qwen-7B | Qwen2.5-Math-7B |
| DeepSeek-R1-Distill-Llama-8B | Llama-3.1-8B |
| DeepSeek-R1-Distill-Qwen-14B | Qwen2.5-14B |
| DeepSeek-R1-Distill-Qwen-32B | Qwen2.5-32B |
| DeepSeek-R1-Distill-Llama-70B | Llama-3.3-70B-Instruct |
随着MoE架构大模型的快速推广,产业界也有看法认为在单块GPU上集成更大的超过对等算力的显存或扩展存储显得尤为重要。
首先要看产品应用场景占有率,其次要看实际的部署方案,最后要看成本比较:
1)根据前面分析,目前主力的专业行业应用仍是使用Dense模型,能部署MoE模型的通用AI巨头早已下场完成部署,从目前的应用比例来看,使用Dense模型的依然占据应用主体。对于Dense模型(实际上是单专家的特例),超过对等算力的单卡大显存或扩展存储容易形成浪费。
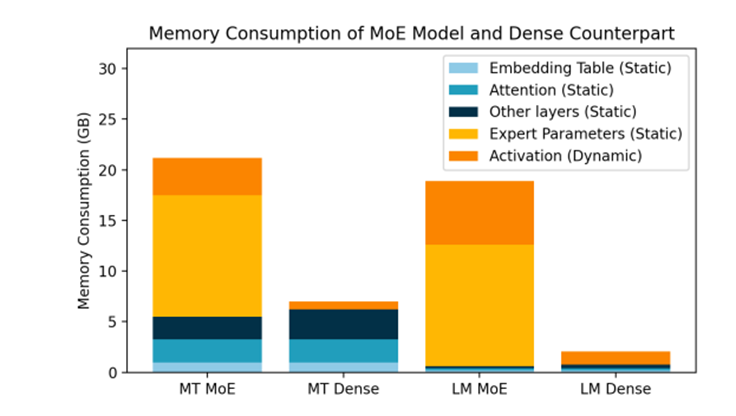
同样模型性能下MoE模型需要更大的显存(来源:Meta)
2)根据从厂商和V3论文获得的实际部署方案,为保证MoE部分不同专家之间的负载均衡,会将共享专家和高负载的细粒度专家在集群的不同GPU做多个复制,让GPU把更多的热数据(发给共享专家的)跑起来,V3部署中每个GPU大概托管9个专家。如果考虑这9个专家中有一个是参数最多的共享专家,那么事实上每块GPU上的空闲细粒度专家占据的参数总和可能不超过单块GPU上总参数量的1/3。
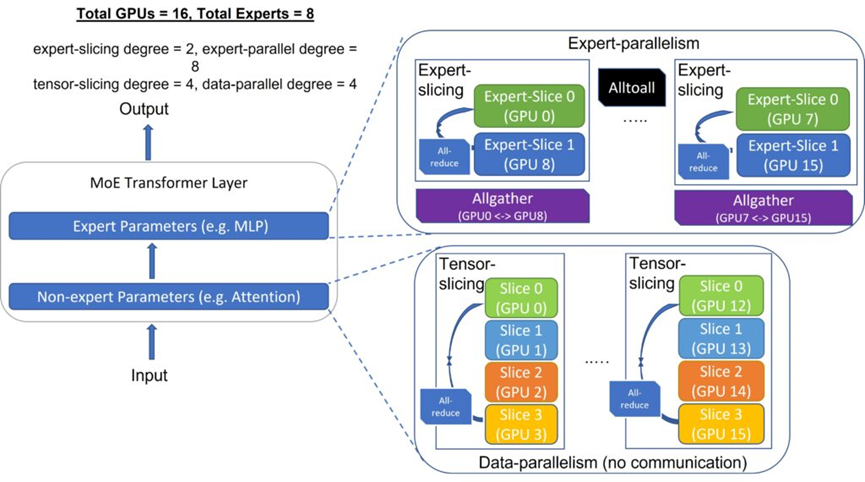
MoE的跨GPU部署模式(来源:微软)
3)从成本上看,可能把一部分专家放到CPU上更划算。MoE上的专家可以分为高频专家、中频专家,低频专家。高频专家和中频专家搭配部署在GPU上比较合适,低频专家调度很少,更适合放在服务器上已有的闲置CPU的内存上(CPU上的标准内存比GPU的HBM便宜很多,扩展性更好),以充分利用全服务器的算力降低综合成本。
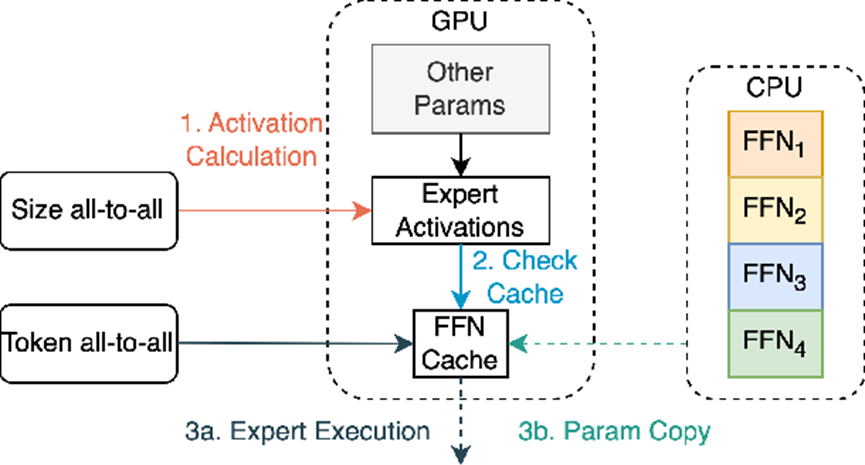
MoE模型的GPU+CPU混合部署(来源:Meta)
另外,R1自己都做Dense模型的蒸馏版本了,为何还要纠结于高于对等算力带宽的超大显存?
DeepSeek-V2以性价比优势领先,引发市场变革。V3和R1开源后,巩固了MoE和AI Infra领导地位,展现卓越推理性能。
R1/V3创新点:
DeepSeek的算法和AI Infra设计可能已超越国际同行,GPU性能使用接近极限,实现软件Scale-up。如此显著的训练效率提升,对大模型领域是一大贡献。
关于DeepSeek R1是否构成国运级别的贡献,以下是我的观点:
1)DeepSeek的成果,尤其是V3/R1的开源,确实值得产业界的极高评价。然而,过度的赞誉可能对DeepSeek不利,可能导致团队分心,甚至可能引起国际政治因素的干预。
2)DeepSeek创始人梁文锋的低调作风值得媒体和社会尊重。支持更多本土人才和企业,以实干精神推动技术进步,对国运的正面影响更为深远。
3)对DeepSeek的评价应基于实际技术分析,避免盲目跟风。实干精神对于追求理想的人来说至关重要。
4)技术不断进步,未来必有超越R1的模型出现。R1是DeepSeek探索之旅中的一颗明珠,但不是终点。
5)是否是OpenAI模型的蒸馏版本并不关键。开源共享是推动大模型技术进步的关键,集多方之力才能推动人工智能的颠覆式发展。
DeepSeek的成就为国产AI芯片的发展提供了以下启示:
1)投资逻辑需要更新,本土研发团队完全有能力创造国际级成果。国产AI芯片不应仅限于追随,而应探索新的架构和技术融合。
2)DeepSeek的成果凸显了算力对模型进步的重要性。提升算力使用效率和发展新架构AI芯片,对于抓住MoE模型发展期的技术红利至关重要。
3)发展3D封装集成、高速互连和开源编译生态,将有助于中国芯片产业在全球竞争中占据有利地位。

今天这个教程颜值相当高,从色偏的角度,教同学们把皮肤修得白皙好看,特别适合妹子或有妹子的男生,附上高...
去看看>>
“《連城》作品系列展出的各張攝影作品各具主題,但離不開中心主旨:琴澳關係。”鏡頭中的95後澳門青年攝...
去看看>>
每个插画师的创作方式都不一样,有人喜欢将画面构思好了再动笔,而我比较喜欢从一堆杂乱的色彩和线条中理清...
去看看>>
北京青年美術雙年展是立足北京、輻射京津冀、面向全國的綜合性青年藝術展示、學術交流、藝術家培養平台,是...
去看看>>
官宏滔摄影作品、吴析夏三维装置作品展
去看看>>
随着时代更迭、科技创新 人们的媒体生活不再平面 如今,我们以多面立体的生活方式 感受着这个瞬息万变的...
去看看>>
这是一个忙碌而躁动的时代,我们每天都在接受海量信息的洗礼,而手机是我们接受信息冲击的最前线,每天都有...
去看看>>
先阅读【开发工具】部分,确保开发环境可以编写代码并运行。然后学习【数据分析】或【Python小游戏开...
去看看>>
Mybatis工作流程可以大致分为四个步骤:加载配置并初始化、接收调用请求、处理操作请求 触发条件:...
去看看>>
连城琴澳摄影/装置艺术展 圆满举办
去看看>>