
大模型的训练和推理,离不开精度,其种类很多,而且同等精度级别下,还分不同格式。比如:
浮点数精度:双精度(FP64)、单精度(FP32、TF32)、半精度(FP16、BF16)、8位精度(FP8)、4位精度(FP4、NF4)
量化精度:INT8、INT4 (也有INT3/INT5/INT6的)
另外,实际使用场景中,还有多精度和混合精度的概念
假设你每秒钟赚到的钱是1块钱,那一个月的收入是1*60*60*24*30=216000,如果每秒钟赚到1块1呢,那一个月的收入是237600,就一个1毛钱的小数点,让你月收入少了1万多,这就是精度不同导致的差异。
典型的例子是π,常用3.14表示,但是如果要更高精度,小数点后面可以有无数位。
当然,这些都是数学里面的精度概念,在计算机里面,浮点数的精度,跟存储方式有关,占用的bit越多,精度越高。
因为成本和准确度。我们都知道精度高肯定更准确,但是也会带来更高的计算和存储成本。较低的精度会降低计算精度,但可以提高计算效率和性能。所以多种不同精度,可以让你在不同情况下选择最适合的一种。
双精度比单精度表达的更精确,但是存储占用多一倍,计算耗时也更高,如果单精度足够,就没必要双精度。
在计算机中,浮点数存储方式,由由符号位(sign)、指数位(exponent)和小数位(fraction)三部分组成。符号位都是1位,指数位影响浮点数范围,小数位影响精度。
Floating Point,是最原始的,IEEE定义的标准浮点数类型。由符号位(sign)、指数位(exponent)和小数位(fraction)三部分组成。
FP64,是64位浮点数,由1位符号位,11位指数位和52位小数位组成。

FP32、FP16、FP8、FP4都是类似组成,只是指数位和小数位不一样。但是FP8和FP4不是IEEE的标准格式。
FP8是2022年9月由多家芯片厂商定义的,论文地址:https://arxiv.org/abs/2209.05433
FP4是2023年10月由某学术机构定义,论文地址:https://arxiv.org/abs/2310.16836
FP8格式有两种变体,E4M3(4位指数和3位尾数)和E5M2(5位指数和2位尾数)
符号位、指数位、小数位的位数如下表所示:
| 格式 | 符号位 | 指数位 | 小数位 | 总位数 |
| FP64 | 1 | 11 | 52 | 64 |
| FP32 | 1 | 8 | 23 | 32 |
| FP16 | 1 | 5 | 10 | 16 |
| FP8 E4M3 | 1 | 4 | 3 | 8 |
| FP8 E5M2 | 1 | 5 | 2 | 8 |
| FP4 | 1 | 2 | 1 | 4 |
[特殊精度]
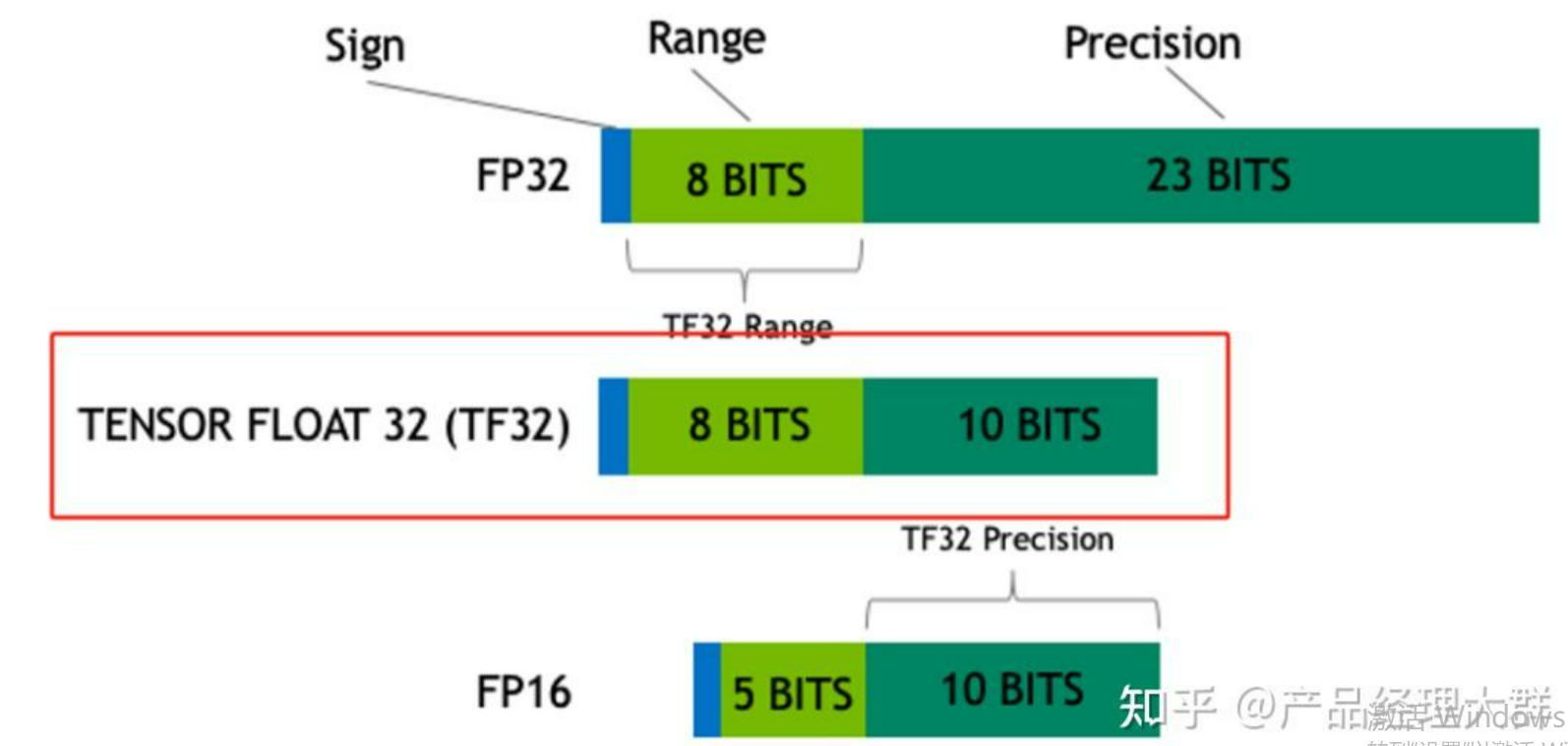
TF32,Tensor Float 32,英伟达针对机器学习设计的一种特殊的数值类型,用于替代FP32。首次在A100 GPU中支持。
由1个符号位,8位指数位(对齐FP32)和10位小数位(对齐FP16)组成,实际只有19位。在性能、范围和精度上实现了平衡。
python中查看是否支持:
import torch
//是否支持tf32
torch.backends.cuda.matmul.allow_tf32
//是否允许tf32,在PyTorch1.12及更高版本中默认为False
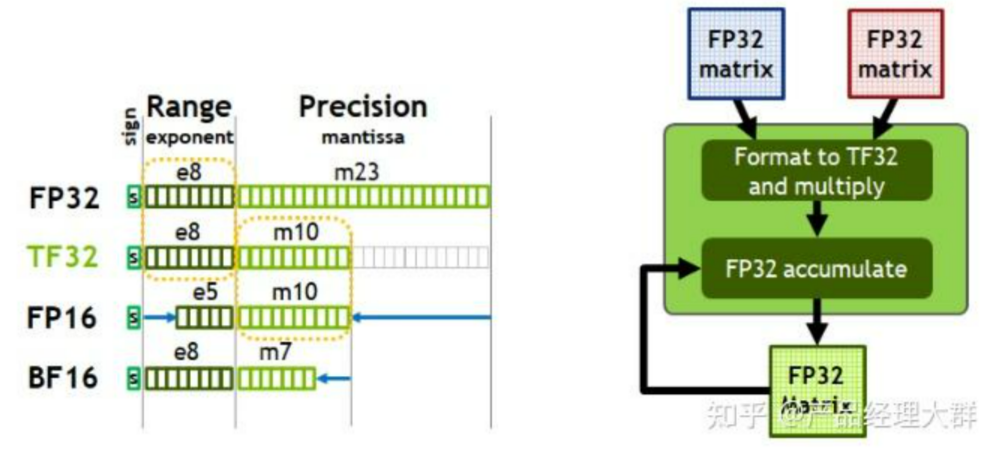
torch.backends.cudnn.allow_tf32BF16,Brain Float 16,由Google Brain提出,也是为了机器学习而设计。由1个符号位,8位指数位(和FP32一致)和7位小数位(低于FP16)组成。所以精度低于FP16,但是表示范围和FP32一致,和FP32之间很容易转换。
在 NVIDIA GPU 上,只有 Ampere 架构以及之后的GPU 才支持。
python中查看是否支持的指令:
import transformers
transformers.utils.import_utils.is_torch_bf16_gpu_available()NF4,4-bit NormalFloat,一种用于量化的特殊格式,在QLoRA量化论文中提出。
NF4是建立在分位数量化技术的基础之上的一种信息理论上最优的数据类型。把4位的数字归一化到均值为 0,标准差为 [-1,1] 的正态分布的固定期望值上,知道量化原理的应该就会理解。
FP精度和特殊精度加上,位数总结如下表
| 格式 | 符号位 | 指数位 | 小数位 | 总位数 |
| FP64 | 1 | 11 | 52 | 64 |
| FP32 | 1 | 8 | 23 | 32 |
| TF32 | 1 | 8 | 10 | 19 |
| BF16 | 1 | 8 | 7 | 16 |
| FP16 | 1 | 5 | 10 | 16 |
| FP8 E4M3 | 1 | 4 | 3 | 8 |
| FP8 E5M2 | 1 | 5 | 2 | 8 |
| FP4 | 1 | 2 | 1 | 4 |
在计算领域,多精度计算与混合精度计算是两种重要的优化策略。多精度计算通过在不同场景下灵活选用半精度、单精度或双精度等不同精度模式,精准匹配计算需求,既确保了关键部分的高精度处理,又在其他环节有效降低了资源消耗。而混合精度计算则更为巧妙,它在同一操作中巧妙融合多种精度级别,实现了在保持计算精度的前提下,显著提升计算效率,大幅减少运行所需的内存占用、计算时间和功耗消耗,为高效计算开辟了新路径。
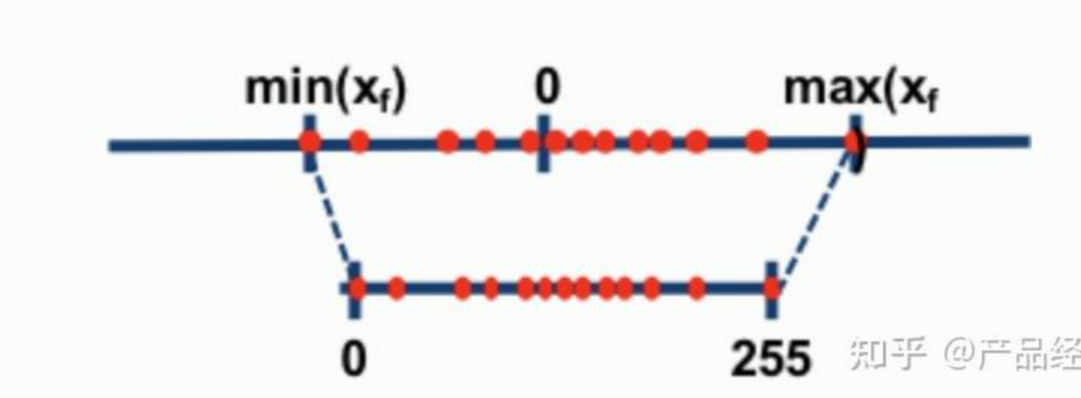
一般情况下,精度越低,模型尺寸和推理内存占用越少,为了尽可能的减少资源占用,量化算法被发明。FP32占用4个字节,量化为8位,只需要1个字节。
常用的是INT8和INT4,也有其他量化格式(6位、5位甚至3位)。虽然资源占用减少,但是推理结果差不了多少。
以下是一些常见的大模型量化算法,这些算法主要用于减少模型的存储和计算需求,同时尽量保持模型的性能
这些量化算法在实际应用中可以根据模型的具体需求和硬件环境进行选择和组合,以实现最佳的性能和效率平衡。
本文全面介绍了大模型训练和推理中不同精度类型及其应用。精度分为浮点数精度(如FP64、FP32、FP16、FP8、FP4)和量化精度(如INT8、INT4),还有多精度和混合精度概念。不同精度在成本和准确度间权衡,高精度更准确但成本高,低精度效率高但精度低。浮点数精度由符号位、指数位和小数位组成,不同格式位数不同,如FP8有E4M3和E5M2两种变体。特殊精度如TF32、BF16和NF4针对特定需求设计。量化算法(如权重量化、激活量化、混合精度量化等)通过减少模型存储和计算需求来优化性能,同时尽量保持模型精度。这些技术和算法可根据具体需求和硬件环境选择组合,以实现最佳效果。

今天这个教程颜值相当高,从色偏的角度,教同学们把皮肤修得白皙好看,特别适合妹子或有妹子的男生,附上高...
去看看>>
“《連城》作品系列展出的各張攝影作品各具主題,但離不開中心主旨:琴澳關係。”鏡頭中的95後澳門青年攝...
去看看>>
每个插画师的创作方式都不一样,有人喜欢将画面构思好了再动笔,而我比较喜欢从一堆杂乱的色彩和线条中理清...
去看看>>
北京青年美術雙年展是立足北京、輻射京津冀、面向全國的綜合性青年藝術展示、學術交流、藝術家培養平台,是...
去看看>>
官宏滔摄影作品、吴析夏三维装置作品展
去看看>>
随着时代更迭、科技创新 人们的媒体生活不再平面 如今,我们以多面立体的生活方式 感受着这个瞬息万变的...
去看看>>
这是一个忙碌而躁动的时代,我们每天都在接受海量信息的洗礼,而手机是我们接受信息冲击的最前线,每天都有...
去看看>>
先阅读【开发工具】部分,确保开发环境可以编写代码并运行。然后学习【数据分析】或【Python小游戏开...
去看看>>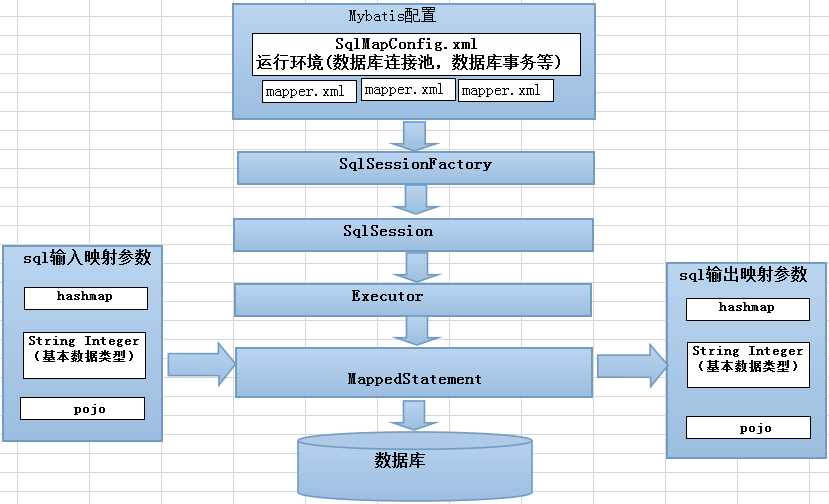
Mybatis工作流程可以大致分为四个步骤:加载配置并初始化、接收调用请求、处理操作请求 触发条件:...
去看看>>
连城琴澳摄影/装置艺术展 圆满举办
去看看>>